Recently, the research group led by Assistant Professor Li Yuanning from the School of Biomedical Engineering (BME) at ShanghaiTech University proposed an efficient acoustic-linguistic dual-pathway framework that achieves reconstruction of sentence-level speech with both naturalness and intelligibility, using only about 20 minutes of high-density electrocorticography (ECoG, a technique that directly records electrical signals from the brain’s cortical surface) data per participant. Their results were published in eLife.
Speech is the most natural form of human communication. Scientists have long sought to understand how the brain encodes speech information, which is not only a core question in cognitive neuroscience but also lays the foundation for brain-computer interface (BCI) technologies—such as helping patients with aphasia (inability to speak) or amyotrophic lateral sclerosis (ALS, also known as Lou Gehrig’s disease) to “speak” directly through brain signals. ECoG technology, with its high temporal and spatial resolution, serves as a key tool for speech decoding, and deep learning algorithms have further accelerated progress in reconstructing speech directly from brain signals. However, the paired brain signal and speech data available in clinical settings is extremely limited (often less than a few hours), making traditional end-to-end models difficult to stabilize. Existing methods typically face a trade-off: one approach reconstructs acoustic features (such as pitch, rhythm, and timbre) for more natural sound but lacks clarity and intelligibility; the other decodes into linguistic units like text or phonemes for easier content understanding but misses real timbre and prosody, resulting in mechanical-sounding voices. The core challenge is: under data-limited conditions, how can we reconstruct complete sentence-level speech that is both natural and clear?
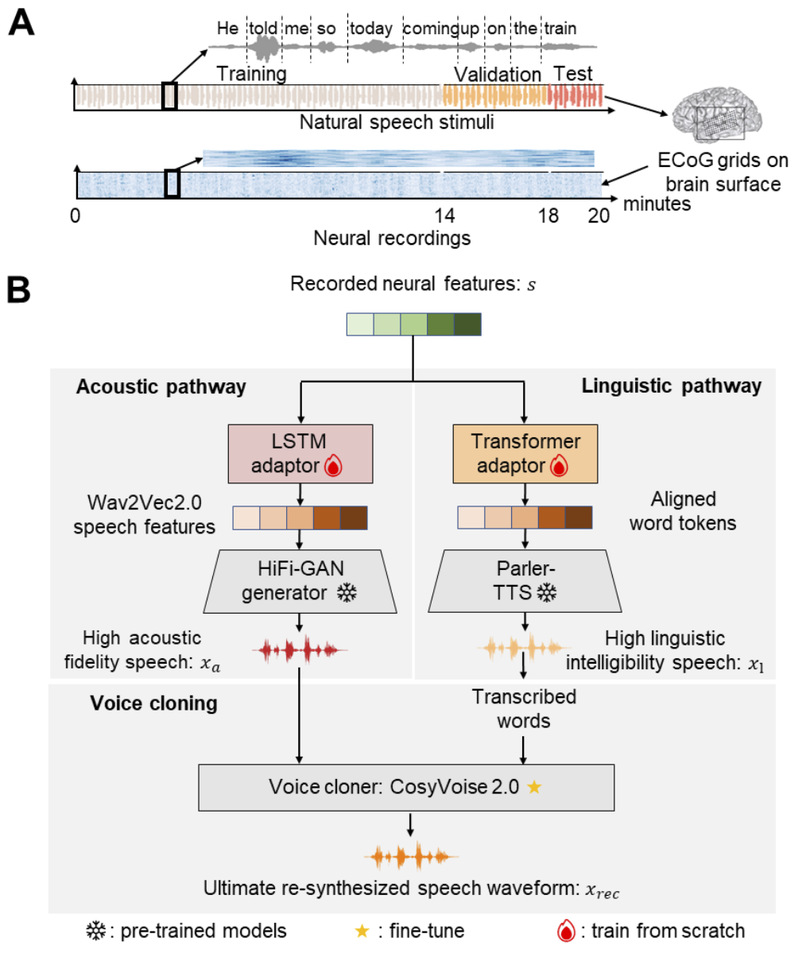
ECoG experimental paradigm and dual-pathway decoding model architecture.
The core innovation of this study is the acoustic-linguistic dual-pathway framework. It cleverly leverages pre-trained speech and AI generative models (which have learned general knowledge from vast amounts of data) to achieve efficient reconstruction under small-sample brain signal conditions. Specifically, the acoustic pathway focuses on capturing “surficial” details of sound, such as pitch, rhythm, and the speaker’s unique timbre, making the reconstructed speech sound more authentic and natural; the linguistic pathway concentrates on decoding more “technical” content, such as words and sentence structures, ensuring the reconstructed speech is accurate and intelligible. The results from the two pathways are then fused through voice cloning technology to generate the final speech output. This not only improves reconstruction quality (mean opinion score approaching 4.0/5.0, word error rate of only 18.9%) but, more importantly, validates the hierarchical representation of speech in the brain: the acoustic richness and linguistic intelligibility can be optimized separately and then synergized. From a broader Neuro-AI (neuroscience and artificial intelligence integration) perspective, this work pioneers a new paradigm—using prior knowledge from AI foundation models combined with brain signal constraints—to reduce data requirements for BCIs, enhance usability, and provide valuable insights for research on aligning brain science with AI representations, such as how AI can better simulate human brain processing of speech.
BME PhD student Li Jiawei is the first author of the paper. Professor Li Yuanning is the corresponding author.