Prof. Gao Shenghua’s research group from the Visual & Data Intelligence Center focuses on using deep learning and sparse/low-rank models to explore the low-dimensional structure in huge high-dimensional data, and uses it to solve practical computer vision problems, including target recognition, action recognition, image or video generation, 3D reconstruction, etc. Recently the group published four papers in the IEEE Conference on Computer Vision and Pattern Recognition (CVPR2021) describing their recent achievements in the related fields. The following are brief introductions.
1. Layout-guided novel view synthesis from a single indoor panorama
Existing view synthesis methods perform well on perspective images. However, due to the limited field-of-view of the perspective camera, the synthesis performance decreases sharply with the increase in camera displacement. In this research, Gao's group undertook the first attempt at generating views from a single indoor panorama and took the large camera displacement into consideration. The researchers first used convolutional neural networks (CNNs) to extract the deep features and estimate the depth map from the source-view image. Their method then leveraged the prior room layout, a strong structural constraint of the indoor scene, to guide the generation of target views. More concretely, the method estimated the room layout in the source view and transformed it into the target viewpoint as guidance. Meanwhile, the method also constrained the room layout of the generated target-view images to enforce geometric consistency. To validate the effectiveness of the method, Gao's group proceeded to build a large-scale photorealistic dataset containing both small and large camera displacements. The experimental results using the artificial dataset demonstrated that the proposed method achieved state-of-the-art performance on this task. The title of the paper is “Layout-Guided Novel View Synthesis from a Single Indoor Panorama”.
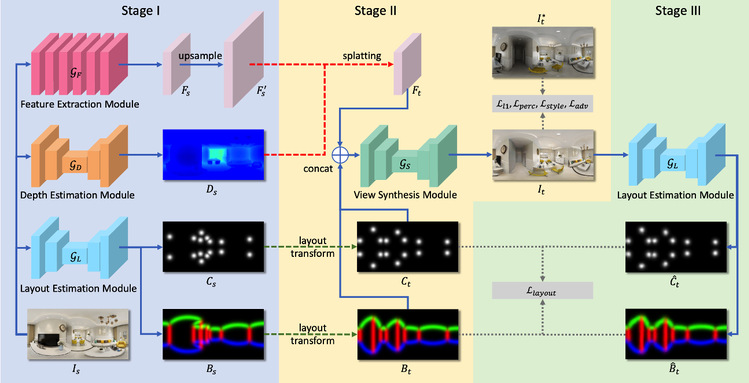
Figure 1. Framework diagram of the proposed algorithm
2. Prior based image inpainting
Human image completion is an important subproblem in image inpainting. It aims to recover the corrupted single-person image and generate a plausible result. For a long time, the problem of single-person image completion has not been well solved. Now, the group proposed a prior based human part completion model.
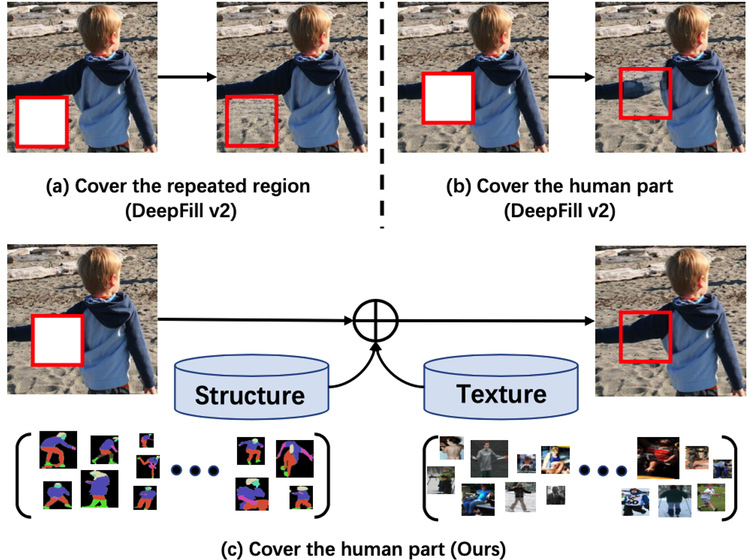
Figure 2. The difference between prior-based human body completion and traditional image completion algorithms
In this model, different from the current models that utilize neural networks to learn structural information of images, the group proposed to leverage semantic segmentation maps as prior structures to characterize human body structure, which can not only explicitly guide the human part completion, but also provide semantic information in extracted feature maps to recover human structure. In addition, a memory bank module was designed and embedded in the model to provide a prior structure-texture correlation, thus allowing more vivid textures to be recovered. The following framework shows the details of the model.
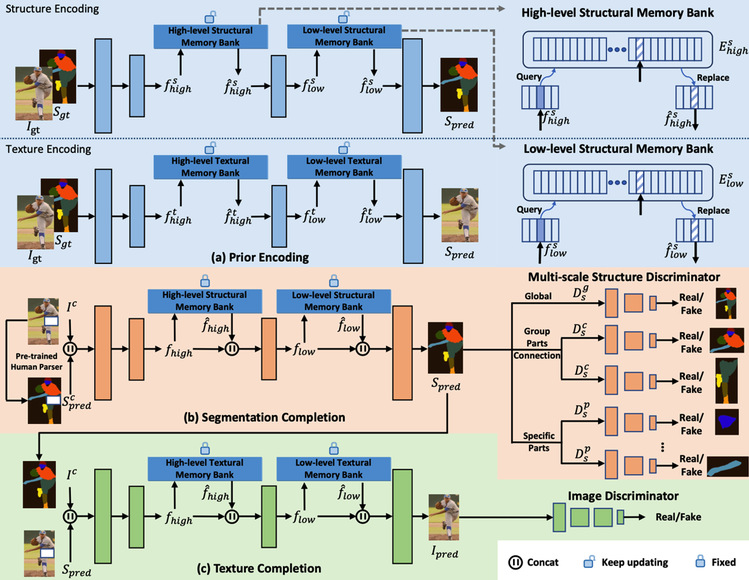
Figure 3. Model framework
This model was tested and verified on two public large-scale datasets (LIP and ChictopiaPlus) and was proved effective.
3. Landmark feature convolution for visual grounding
Visual grounding, aimed at locating the most relevant object in an image according to a natural language expression, is one of the fundamental visual-language problems and the key to realizing human-computer interaction. In natural language expressions, people often describe an object by describing its location relationship with other entities, e.g., laptop on the table, thus, understanding their location relationships is vital in visual grounding. Since the distance between two entities in a language expression can be undefined and direction-related, Gao’s group hypothesized that long-range and direction-aware context should be considered in object locating.
Long-range modeling is a long-standing but unsolved problem in computer vision. Existing convolution operations have apparent limitations in the receptive field since they sample a fixed number of locations for aggregation. To illustrate, given the same number of parameters, the receptive field of a convolution operation is either dense but small (standard convolution) or large but sparse (dilated convolution). In this research, Gao’s group proposed a convolution algorithm based on region sampling. For each location, they divided the whole feature map into several sampling regions based on the current location and updated the representation by aggregating the sub-regions so that the operator has a global receptive field. Experiments showed that the proposed convolution is advantageous to related modules in terms of efficiency or effectiveness.
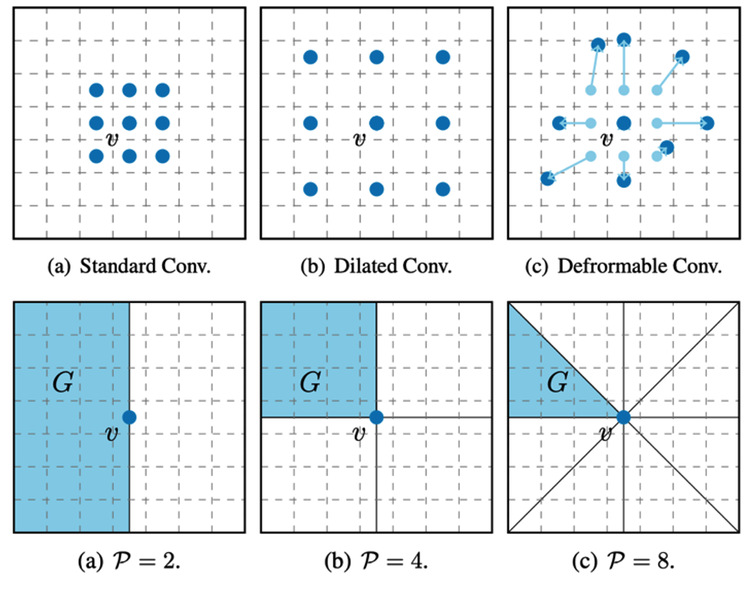
Figure 4. Comparison of two convolution operations. The first row shows the convolution based on pixel. The second row shows the convolution based on region
The published paper is entitled “Look Before You Leap: Learning Landmark Features For One-Stage Visual Grounding”. Second year Master student Huang Binbin is the first author, and his mentor, Prof. Gao Shenghua is the corresponding author.
4. Learning to recommend keyframes for interactive video object segmentation in the wild
The title of the fourth paper is “Learning to Recommend Frames for Interactive Video Object Segmentation in the Wild”. To reduce the cost of human annotations, interactive video object segmentation (VOS) aims to achieve promising results with little human supervision. Therefore, it is vital to recommend keyframes to improve the overall quality of video object segmentation.
This paper formulates the frame selection problem in the interactive VOS as a Markov Decision Process, where an agent learns to recommend the frame under a deep reinforcement learning framework. This trained agent can then automatically determine the most valuable frame, making the interactive setting more practical in the wild. Experimental results on public datasets showed the effectiveness of our trained agent without any changes to the underlying VOS algorithms, and the trained agent can surpass human annotators in terms of accuracy and efficiency.
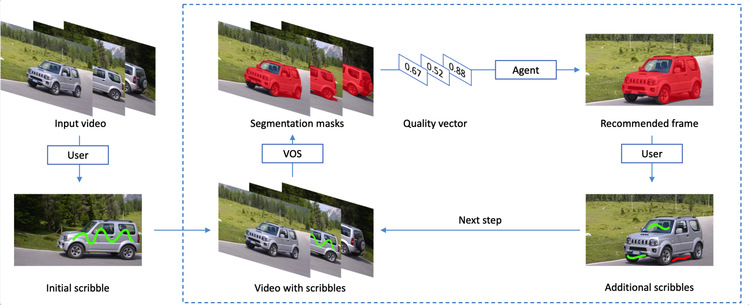
Figure 5. Framework proposed to do the object segmentation