近日,在全球顶尖数据科学竞赛平台Kaggle举办的“Deep Past Challenge(深邃历史挑战赛)”中,由上海科技大学DataTech社团主导组建的参赛队伍,凭借扎实的技术功底与严谨的科研方法,在全球2673支队伍中脱颖而出,一举夺得赛事全球总冠军,展现了上科大学子在人工智能前沿领域的硬核实力。
Kaggle作为Google旗下的全球性数据科学与机器学习平台,是目前全球规模最大、认可度最高的AI竞赛平台之一。本次赛事由深邃历史倡议组织(Deep Past Initiative)主办,聚焦AI技术解决人类文明遗产破译的难题。本次赛事共吸引了来自全球的3311名开发者参与,累计提交方案6.8万份。
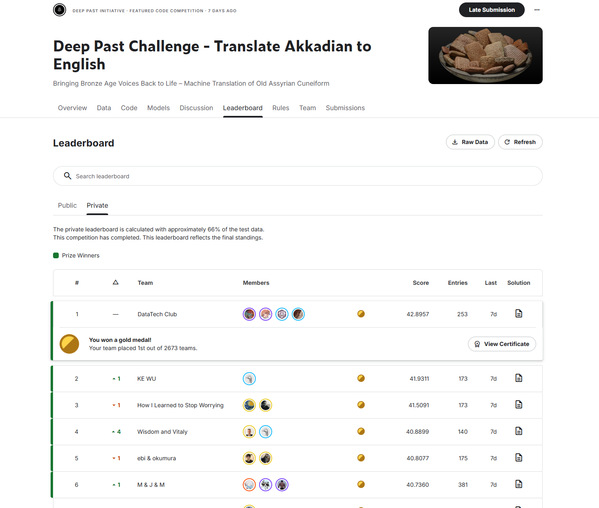
图1 DataTech战队排名第一
本次竞赛聚焦人类文明遗产保护的全球性难题,要求参赛者开发AI系统,实现距今4000多年前的古亚述语(阿卡德语方言)楔形文字音译本的英文翻译。古亚述楔形文字多镌刻于泥板,记录债务、契约、日常事务等内容,是研究古代文明的重要史料。这类记录在泥板上的文字是研究古代文明的关键,但全球能破译的专家不足十人,且现存泥板多有破损,数据稀缺,对AI技术提出了极限挑战。
面对难题,以上科大学生为核心的团队展现了出色的科研组织与攻关能力。团队由上科大信息科学与技术学院2022级本科生洪沐天、2025级本科生李政儒、2023级本科生王越汀,并联合厦门大学2022级本科生顾国勤共同组成。成员们优势互补,紧密协作,展现出出色的技术执行力与创新思维。备赛期间,信息学院为团队提供算力资源支持,为复杂模型训练与技术迭代提供坚实保障。
图2 团队解决方案
参赛过程中,团队确立“数据质量决定模型效果”的核心思路,开展系统性技术攻关。团队摒弃质量欠佳的官方原始数据,依托前沿视觉大模型从海量古籍文献中精准提取高质量古文字——英文对照语料,设计专业提示词实现文本格式规整、空间信息对齐与关键特征锚定。针对数据稀缺问题,团队结合古文字字典与大语言模型,生成符合古代语法与历史语境的模拟语料,有效扩充训练数据规模。最终,团队完成11个深度优化模型的训练与集成,并通过模型量化、并行计算等技术提升推理效率,在赛事规定时限内完成全部计算任务,以显著优势登顶赛事榜单。
上科大团队在此次赛事中的优异表现,充分展现了上科大学生在数据科学与人工智能领域的创新实践能力。团队研发的技术方案,为楔形文字泥板的自动化破译提供了可落地的技术路径参考,将助力古文明遗产研究与保护相关工作的推进。
 沪公网安备 31011502006855号
沪公网安备 31011502006855号