近日,上海科技大学信息科学与技术学院智能网络中心(NICE)文鼎柱课题组在通信领域国际学术期刊 IEEE Journal on Selected Areas in Communications (JSAC) 上发表了题为 “FedLoDrop: Federated LoRA with Dropout for Generalized LLM Fine-tuning” 的研究成果,创新性地提出了 FedLoDrop 框架,通过引入随机丢弃机制,攻克了大模型在边缘网络中微调时“泛化性差”与“通信压力大”的双重挑战。
随着ChatGPT、LLaMA 等大语言模型的广泛应用,业界越来越关注如何针对特定下游任务进行微调。然而,在实际应用场景中,数据往往分布在千家万户的手机、平板或智能设备中,传统的集中式微调面临着严峻的隐私安全挑战。联邦学习(Federated Learning)作为一种分布式训练模式,成为了大模型微调的选择。但在边缘网络环境下,现有的联邦微调技术面临着两大瓶颈。一方面是性能瓶颈,由于终端数据量有限且多样,模型在微调过程中极易陷入“过拟合”,即虽然在本地数据上表现优异,但面对新任务时泛化能力不足。另一方面是资源瓶颈,边缘设备在计算功耗和通信带宽上极为受限,频繁的参数同步会造成巨大的网络延迟和电量消耗。
针对上述痛点,研究团队提出了名为FedLoDrop 的创新框架。该框架将传统机器学习的 Dropout(随机丢弃) 机制引入到了目前最流行的低秩适配微调(LoRA)过程中。不同于传统的 Dropout 随机丢弃神经元,FedLoDrop 专门针对 LoRA 的低秩矩阵进行行列级别的随机采样。在每一轮训练中,服务器会根据预设的丢弃率,为不同的参与设备生成独特的“随机子适配器”。这种设计带来了显著的性能增益。
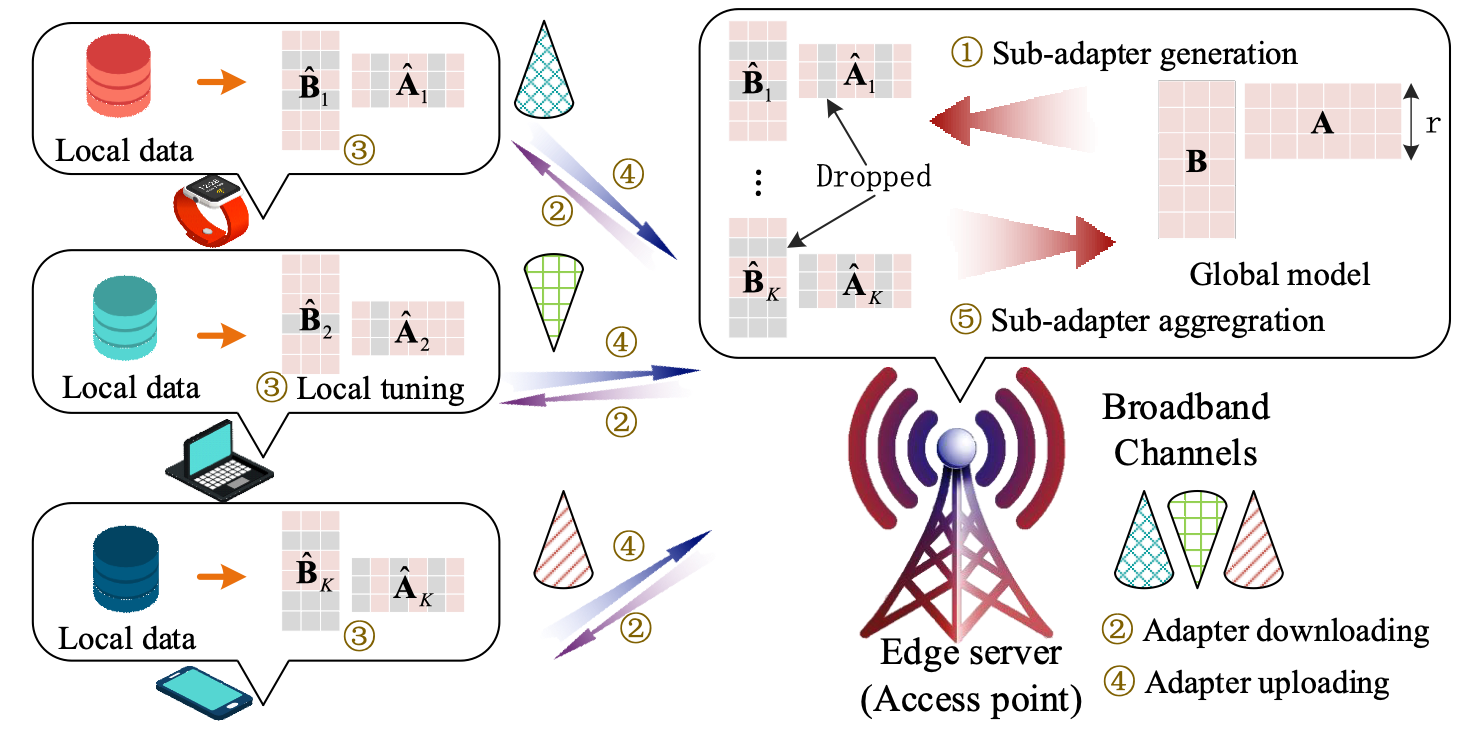
图1:FedLoDrop的具体训练流程
本研究不仅在工程实践上极具创新性,更在理论层面有坚实基础。团队利用逐点假设稳定性理论,首次推导出带Dropout 的联邦 LoRA 泛化误差界限。这一理论揭示了丢弃率、模型稀疏度与训练效果之间的权衡关系。此外,考虑到边缘设备复杂多变的运行环境和资源紧缺,团队还设计了资源优化方案。该方案能够根据当前设备的可用资源以及泛化性能需求,通过复杂的数学优化算法(如分支定界与逐次凸近似),确定最优的丢弃率和资源分配比例,确保在极端环境下依然能获得最佳的模型性能。
实验验证在RoBERTa、LLaMA-7B 以及拥有 340 亿参数的大模型 Yi-34B 上进行了广泛测试。基于GLUE 和 MMLU 等全球公认的权威测评基准上,FedLoDrop 展现出了卓越的泛化性能。
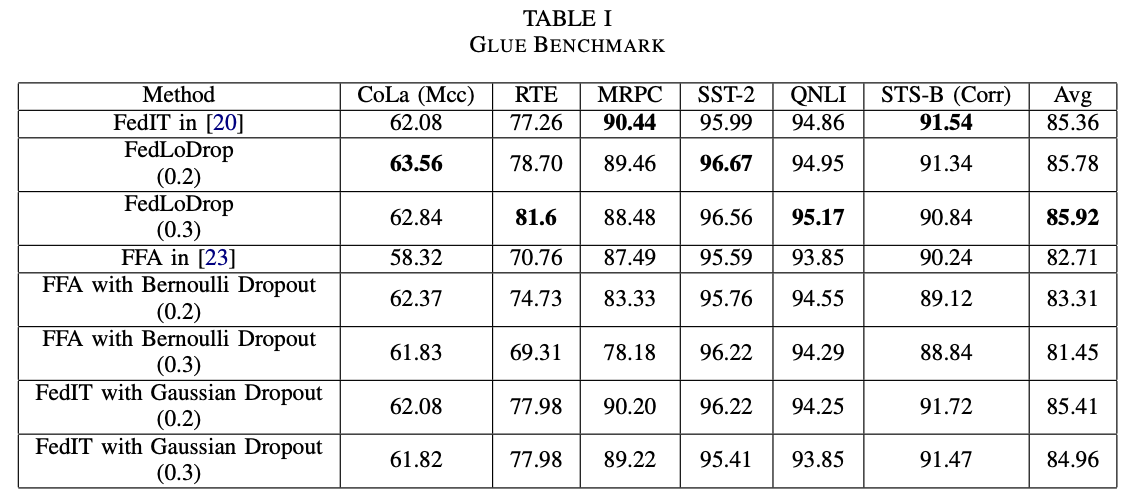
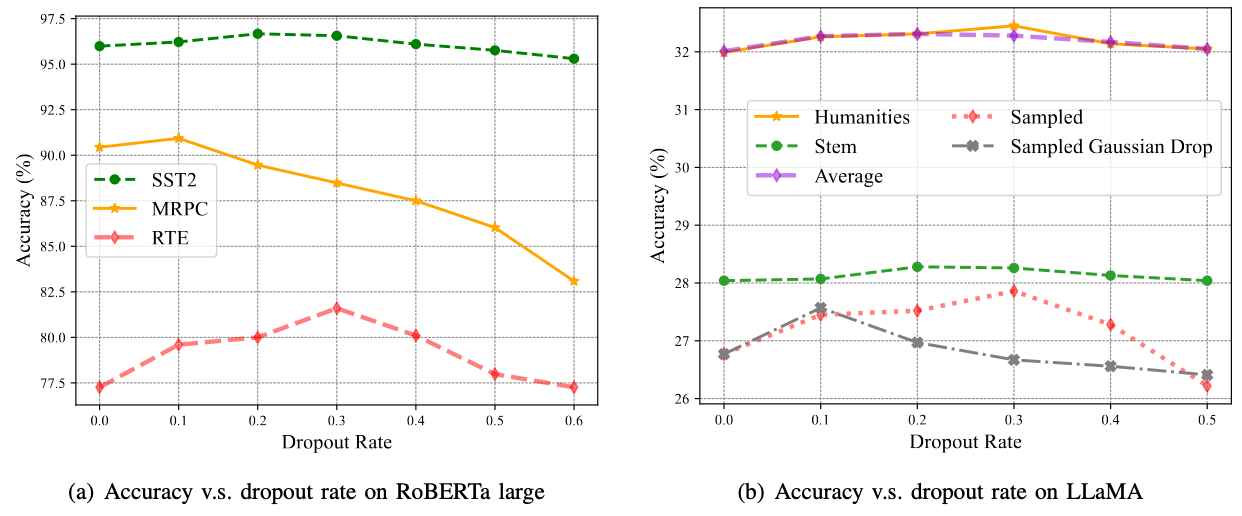
图2:丢弃率在不同模型不同数据集上的性能表现
上海科技大学是该成果的第一完成单位。信息学院2023级博士研究生谢思静为第一作者,信息学院文鼎柱教授为通讯作者。
 沪公网安备 31011502006855号
沪公网安备 31011502006855号