近日,国际计算机视觉与模式识别会议(IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2025)在美国田纳西州召开。作为计算机视觉领域全球重要学术会议之一,本届CVPR会议共收到13008份有效投稿,最终录用论文2878篇,录用率为22.1%。上海科技大学信息科学与技术学院师生共有13篇论文成功入选,研究内容涵盖具身智能、三维表达、多模态学习、AI for Society等多个计算机视觉前沿方向,充分展现了学院在该领域的科研实力与国际影响力。
具身智能
AffordDP : 具有可迁移可供性的通用扩散策略
Generalizable Diffusion Policy with Transferable Affordance
基于扩散的策略在机器人操作任务中表现优异,但在处理域外分布时存在局限。本研究提出AffordDP,利用可供性(affordances)增强对未见对象的泛化能力。通过3D接触点和轨迹建模动静态affordances,结合视觉模型和点云配准实现跨类别泛化,并在扩散采样中引入可供性引导优化动作生成。仿真和真实环境中的实验结果表明,AffordDP在性能上持续优于以往的基于扩散的方法,并成功泛化到其他方法无法处理的未见实例和类别。
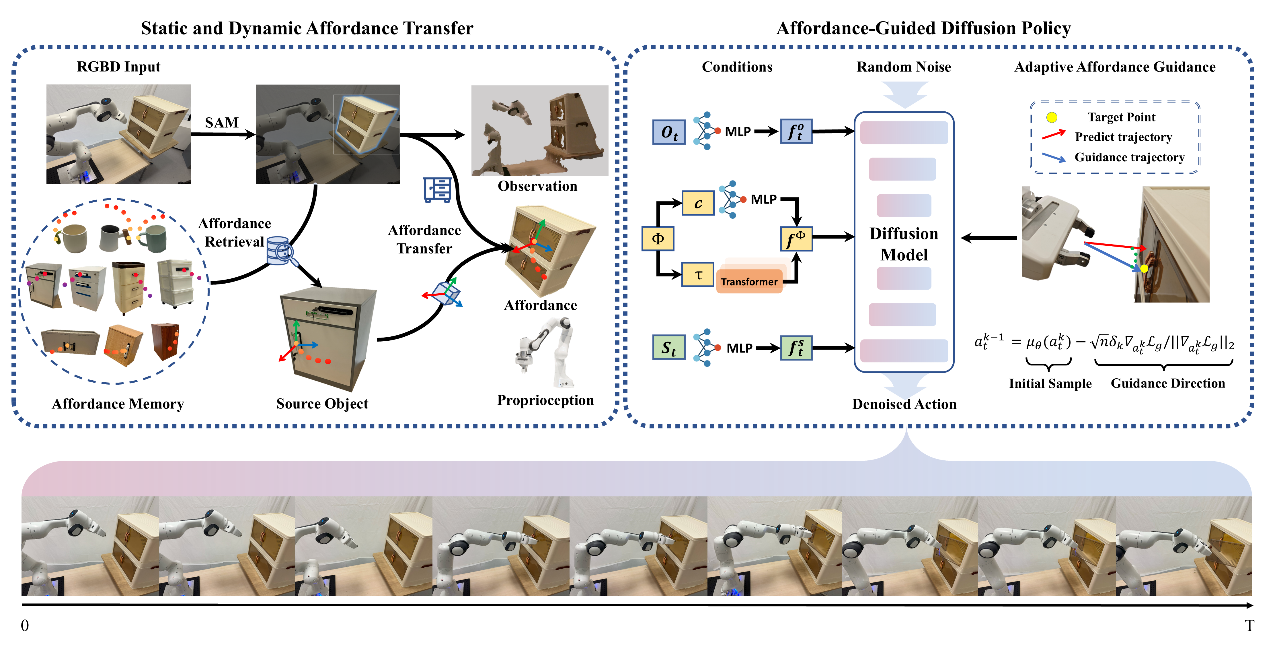
2023级硕士研究生武士杰与朱翌航担任共同第一作者,汪婧雅教授与石野教授担任共同通讯作者。
论文链接: https://arxiv.org/pdf/2412.03142
基于多模态大语言模型的序列化3D可供性推理
Sequential 3D Affordance Reasoning via Multimodal Large Language Model
一个先进的可供性(affordances)分割模型不仅要能理解单个物体的单一功能,还要能够处理复杂的、多步骤的用户指令,识别出一系列的affordance区域。针对这一挑战,本工作提出一种全新的序列化3D affordance推理任务,并开发了SeqAfford模型。SeqAfford基于大规模3D多模态大语言模型(MLLM),能够将复杂的用户指令分解为一系列的affordance分割任务,将语言模型的推理结果与3D点云数据有效结合。在大规模基准测试中,SeqAfford在单affordance和序列化affordance推理任务上均显著优于现有方法,展现了其在开放世界环境中的泛化能力和推理能力。
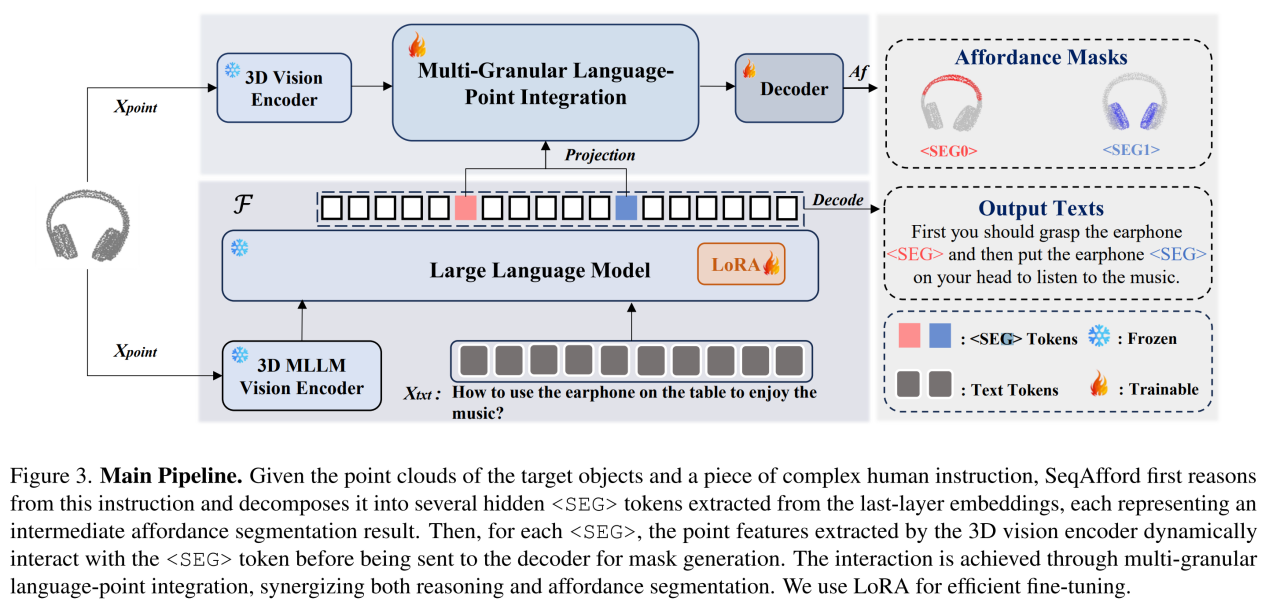
上海科技大学是该成果的第一完成单位,2022级研究生余春霖、2024级研究生王涵情为论文的共同第一作者,汪婧雅教授为通讯作者。
论文链接:https://arxiv.org/pdf/2412.01550
DexGrasp Anything:迈向具有物理感知的通用机器人灵巧抓取
Towards Universal Robotic Dexterous Grasping with Physics Awareness
能够抓取任何物体的灵巧手是开发通用型具身智能机器人的必要条件。由于灵巧手的高度自由度和物体的巨大多样性,以鲁棒的方式生成高质量、可用的抓取姿势是一个重大挑战。本研究提出了一种将物理约束有效地集成到基于扩散的生成模型的训练和采样阶段的方法DexGrasp Anything,可在几乎所有开放数据集中实现最先进的性能。此外团队还提出了一个新的灵巧抓取数据集,包含超过340万种不同的抓取姿势,超过15k个不同的对象,展示了其推进通用灵巧抓取的潜力。
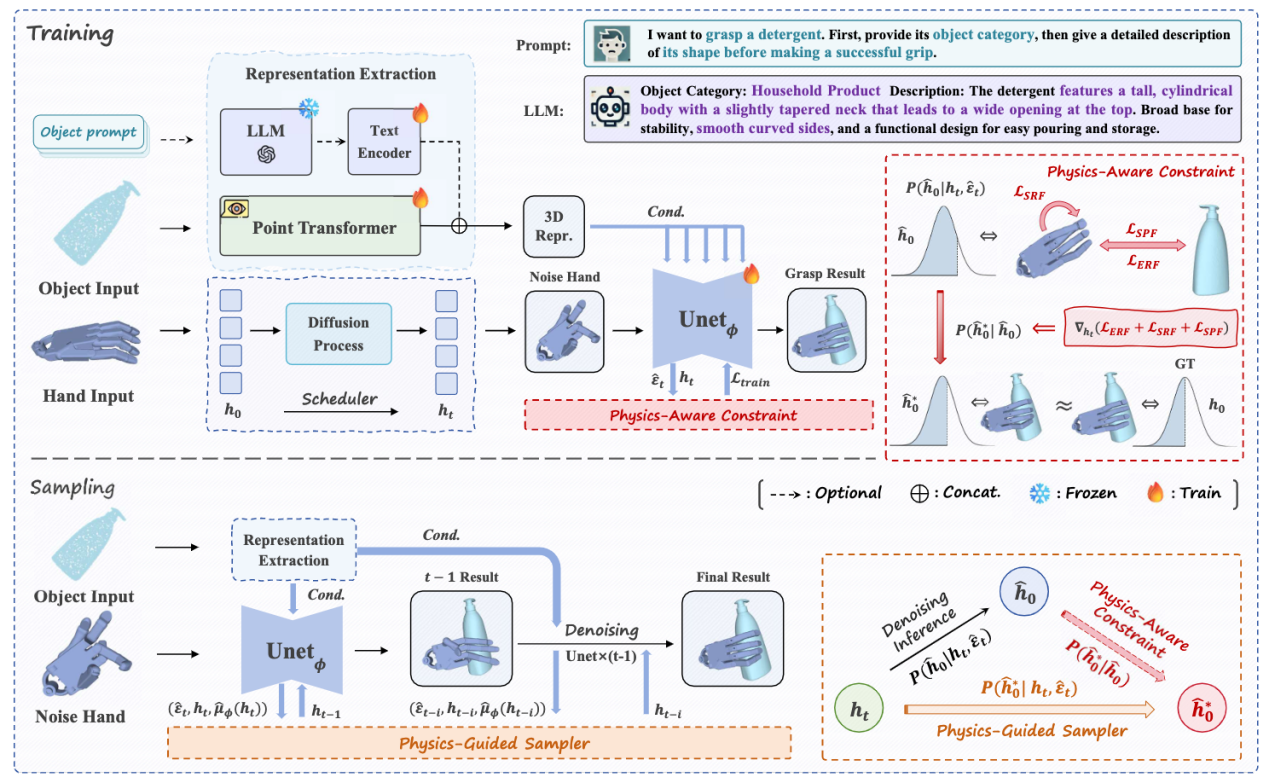
2024级研究生钟奕鸣与2022级姜奇为论文共同第一作者,马月昕教授为论文的通讯作者。
论文链接:https://arxiv.org/pdf/2503.08257
代码链接:https://github.com/4DVLab/DexGrasp-Anything
项目主页:https://dexgraspanything.github.io/
SemGeoMo:具有语义和几何引导的动态情境人体运动生成
Dynamic Contextual Human Motion Generation with Semantic and Geometric Guidance
在给定的动态环境中生成合理和高质量的人类交互运动对于理解、建模、转移和将人类行为应用到虚拟机器人和物理机器人上至关重要,核心在于构建一个面向互动的世界模型,使其能够合理地适应互动对象或人的变化。研究提出一种新的动态上下文人体运动生成方法SemGeoMo,通过将文本描述中的语义信息与从交互对象中提取的层次几何特征综合集成,生成合理、高质量的交互运动,还提高了交互的可解释性和可理解性。该方法在三个数据集上取得了最先进的性能,并在不同的交互场景下展示了优越的泛化能力。
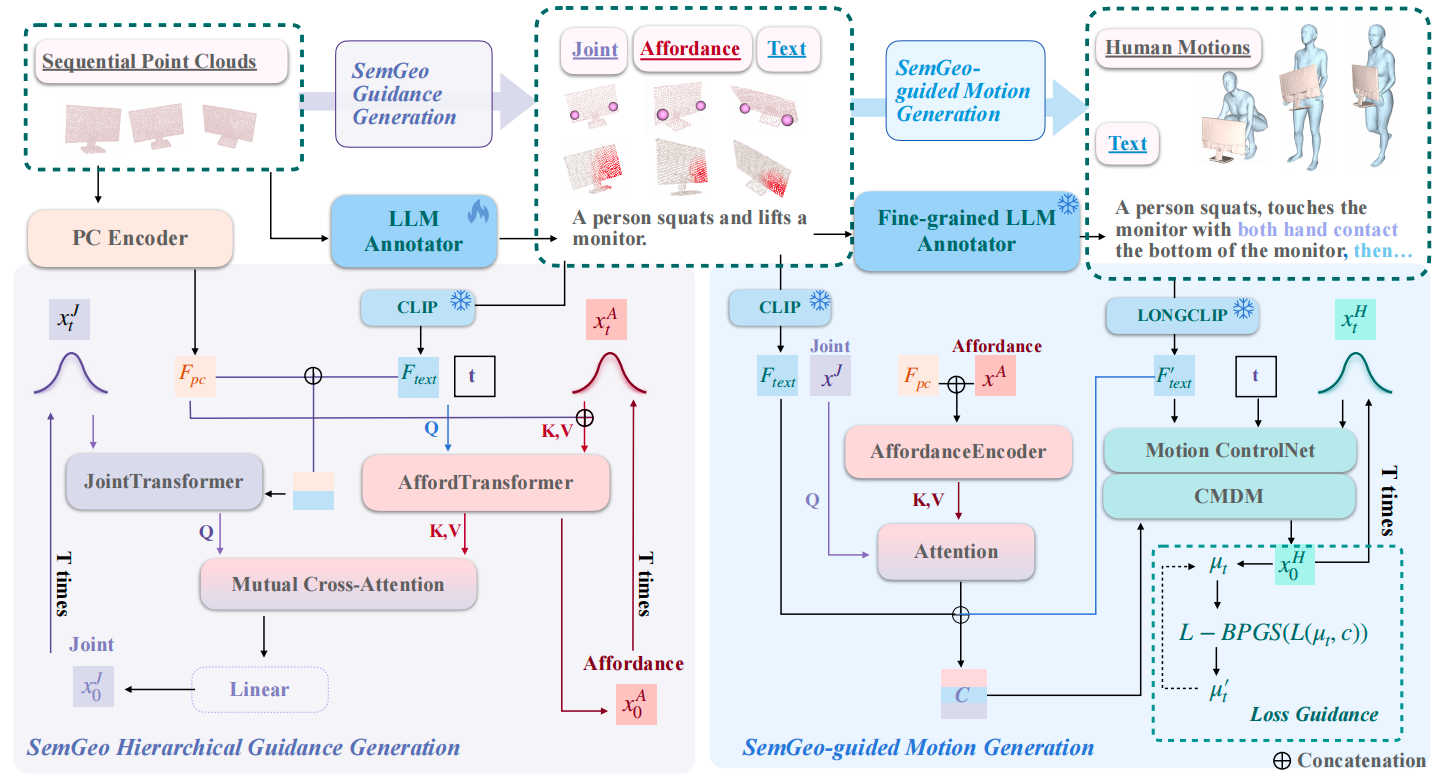
2023级博士生丛培珊与本科生王紫怡为论文共同第一作者,香港中文大学岳翔宇教授和信息学院马月昕教授为共同通讯作者。
论文链接:https://arxiv.org/pdf/2503.01291
代码链接:https://github.com/4DVLab/SemGeoMo
项目主页:https://4dvlab.github.io/project_page/semgeomo/
EasyHOI-大模型驱动的手-物交互重建新方案
Unleashing the Power of Large Models for Reconstructing Hand-Object Interactions in the Wild
从单视角图像中重建手-物交互是一项基础且具挑战性的任务。当前用于分割、修复和3D重建的基础模型在处理真实场景图像时表现出了强大的泛化能力,这为手-物交互的重建提供了可靠的视觉和几何先验。基于这一观察团队提出了一套创新的手-物交互重建方案。多个公开数据集上的实验评估表明,与现有相比该方法在重建的精度和鲁棒性上均具有显著优势,能够从多样化的真实手-物交互图片中准确还原物体的几何形状及交互细节。

访问生刘雨萌为论文的第⼀作者,香港科技大学龙霄潇与信息学院马月昕教授为共同通讯作者。
论文链接: https://arxiv.org/abs/2411.14280
代码链接: https://github.com/lym29/EasyHOI
项目主页: https://lym29.github.io/EasyHOI-page/
三维表达
从回放到真实重演的沉浸式人物体积视频
RePerformer: Immersive Human-centric Volumetric Videos from Playback to Photoreal Reperformance

针对远程通信、教育培训和沉浸式娱乐等应用场景带来颠覆性的视觉体验需求,本工作提出一种基于3D高斯泼溅的全新体积视频生成框架Reperformer,首次实现复杂人物交互场景中的“动态回放–自由重演”协同生成。该方法采用分层解耦策略,并引入自监督学习机制,结合注意力增强的U-Net架构,引入语义感知的动作迁移模块,实现目标动作与原始外观表达的动态匹配,突破了传统动画生成方法对参数化人体模型的依赖,为通用型体积视频生成开辟了新的技术路径。
2020级博士生蒋宇衡和2021级本科生沈哲灏为论文共同第一作者,许岚教授与德国马普研究所Marc Habermann教授为共同通讯作者。
论文链接:https://arxiv.org/pdf/2503.12242
项目主页:https://moqiyinlun.github.io/Reperformer/
图| reperformer算法流程图
BG-Triangle: 基于贝塞尔-高斯三角形的三维矢量化与渲染
Bézier Gaussian Triangle for 3D Vectorization and Rendering
在计算机图形学与3D视觉领域,传统离散几何表示虽能显式精确建模场景,却难以实现端到端的重建优化。神经辐射场(NeRF)实现了可微渲染,但其模糊的几何边界限制了细节捕捉能力。3D Gaussian Splatting(3DGS)提升了渲染效率,但渐变分布的叠加效应仍导致锐利边缘模糊。本研究提出了一种介于离散和连续之间的三维混合表示方法——BG-Triangle,在可微渲染的框架下结合矢量图形和概率建模,利用矢量表达的灵活高效性以更少的图元数量实现更精确的几何和边界建模,为3D场景表示提供了一种新的解决方案。
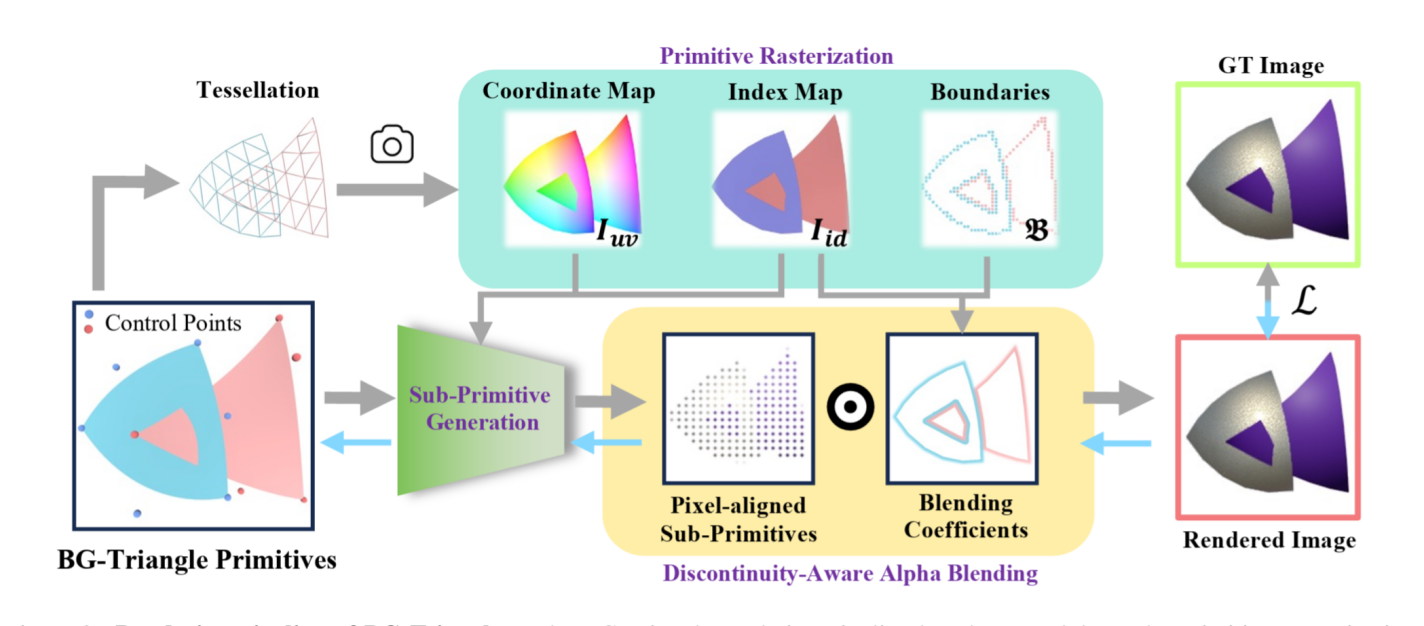
2023级硕士生戴海钊和比利时鲁汶大学博士后吴旻烨为论文共同第一作者,比利时鲁汶大学Tinne Tuytelaars教授和信息学院虞晶怡教授为论文共同通讯作者。
论文链接: https://arxiv.org/pdf/2503.13961
基于回归的几何视觉问题中同伦连续法起始问题-解对的实时模拟
Simulator HC: Regression-based Online Simulation of Starting Problem-Solution Pairs for Homotopy Continuation in Geometric Vision
本研究提出一种基于点对应关系的几何问题求解的新范式,巧妙结合了回归网络、在线对应模拟器和同伦延续三个阶段。回归网络充当通用解近似器,仅需在模拟环境中进行训练。虽然单纯的回归精度往往不足以单独解决问题,但本研究结果表明,其精度通常仍足以模拟出一致的起始问题- 解对,从而成功实现单解延续。
上海科技大学是该成果的第一完成单位,2022级博士生张馨悦为第一作者,Laurent Kneip教授为论文的通讯作者。
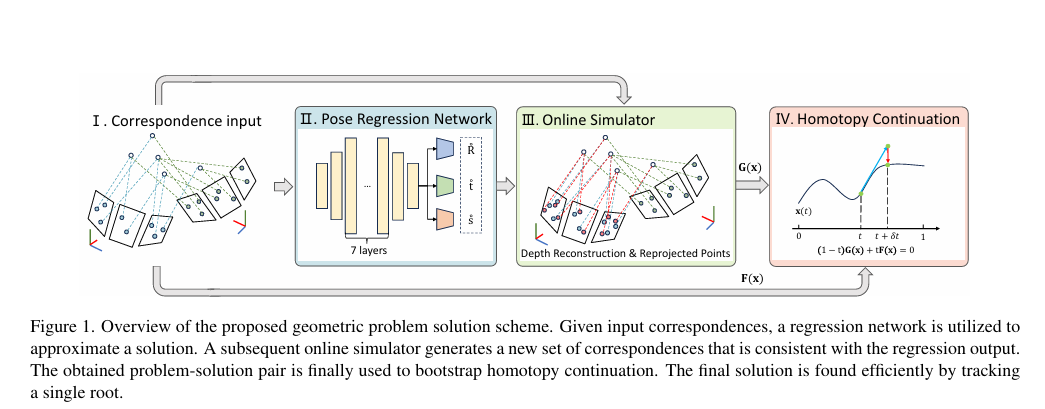
论文链接:https://arxiv.org/pdf/2411.03745
多模态学习
面向带噪标签的基于视觉语言模型的提示学习
NLPrompt: Noise-Label Prompt Learning for Vision-Language Models
基于提示词微调的方法因其强大的任务适应能力而受到广泛关注,本工作面向提示词微调下的带噪标签学习问题,提出了一种新的学习方法NLPrompt,通过引入均值绝对误差(MAE)损失函数和PromptMAE策略,显著增强了模型在噪声标签环境下的鲁棒性,同时保持了高准确率。还提出了基于提示的最优传输数据净化方法,进一步提升模型的性能。实验结果表明,在不同噪声场景下,尤其是在高噪声情况下,NLPrompt表现出了显著的性能提升。
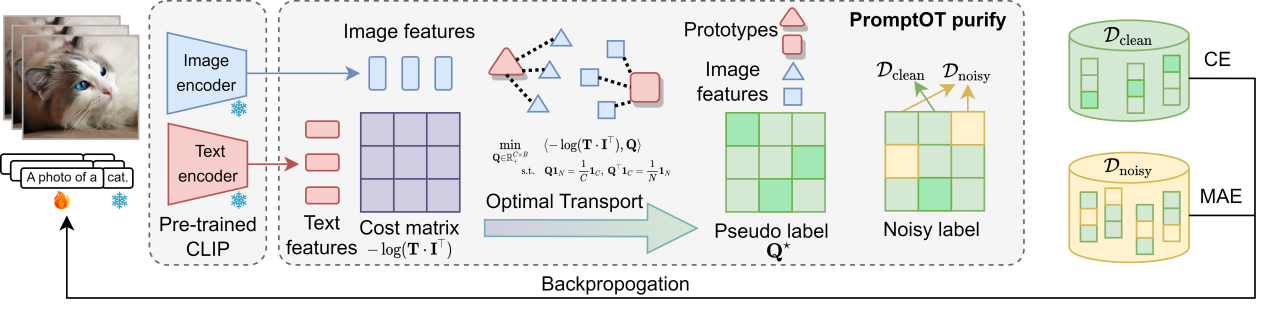
2023级博士生潘比康和2024级硕士生李群为论文共同第一作者,石野教授为通讯作者。
论文链接:https://arxiv.org/abs/2412.01256
代码链接:https://github.com/qunovo/NLPrompt
重新思考基于查询的Transformer在持续图像分割中的应用
Rethinking Query-based Transformer for Continual Image Segmentation
当前基于Transformer架构的统一图像分割器在持续图像分割中面临背景漂移和灾难性遗忘等诸多挑战。本工作重新思考了当前架构下持续学习问题的成因,揭示了Transformer中Query的内在物体感知能力(built-in objectness)对解决持续学习问题的重要意义。从查询(Query)的初始化、蒸馏到重放等多个角度综合解决问题,显著提升了模型在持续分割任务中抗遗忘和学习新知识的能力。实验结果显示该方法在全景分割和语义分割指标上显著优于现有方法,尤其在随机任务序列中表现出更强的鲁棒性,更适应现实世界中的持续学习问题。
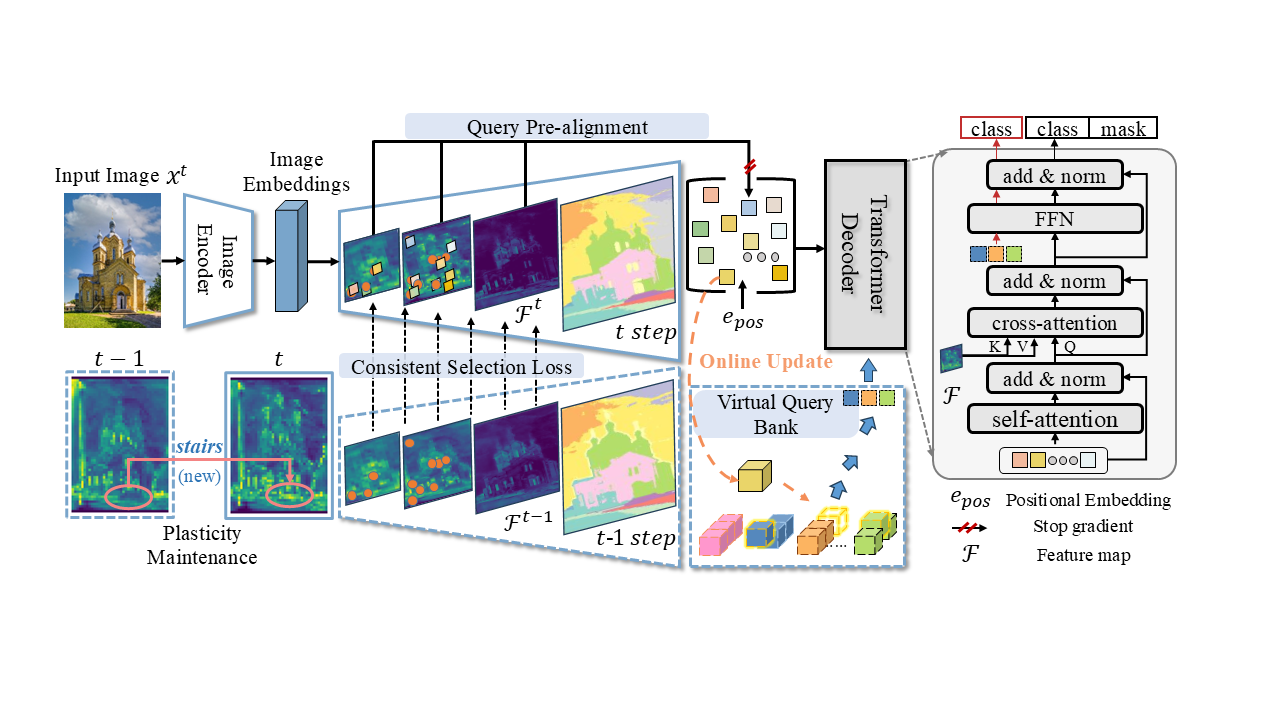
上海科技大学是该成果的第一完成单位。硕士研究生朱宇辰、石骋为共同第一作者,杨思蓓教授为论文的通讯作者。
论文与代码链接:https://github.com/SooLab/SimCIS
面向细粒度泛化类别发现的自适应部件学习方法
Adaptive Part Learning for Fine-Grained Generalized Category Discovery
细粒度视觉识别中,通用类别发现(Generalized Category Discovery, GCD)旨在识别已知和未知类别,但现有方法在细粒度场景下常因部分特征学习不足而性能受限。本研究提出了一种自适应部分学习(Adaptive Part Learning, APL)框架,通过动态聚焦关键局部区域来提升细粒度GCD的准确性,实现了对细微差异的鲁棒建模。多个细粒度数据集上验证结果表明它显著提高了新类别的发现率和分类精度,同时保持了低计算开销。
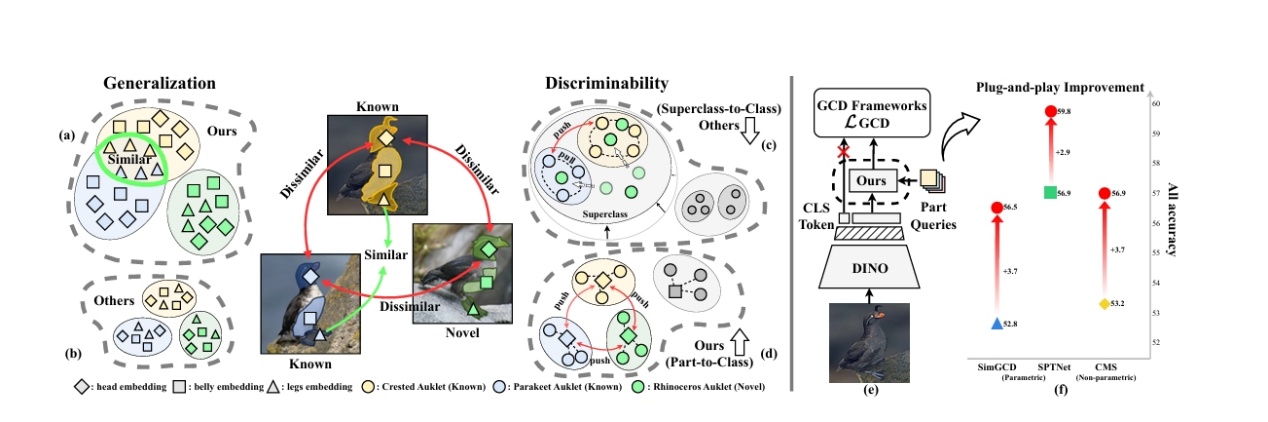
上海科技大学为第一完成单位,博士研究生戴启元、黄涵卓为论文共同第一作者,杨思蓓教授为论文的通讯作者。
通过在线EM 实现更灵活的测试时自适应
Free on the Fly: Enhancing Flexibility in Test-Time Adaptation with Online EM
测试时适应(Test-Time Adaptation, TTA)允许模型在部署时动态调整以适应新数据,但现有方法常受限于计算开销和灵活性不足。本研究提出了一种创新框架“Free on the Fly”,利用在线期望最大化(Online EM)算法,实现了高效且灵活的测试时适应。多个视觉基准任务上的验证结果显示该方法在适应速度和准确性上均优于传统TTA方法,尤其在高动态环境中展现出卓越的鲁棒性,为实时部署的机器学习模型提供了新工具。
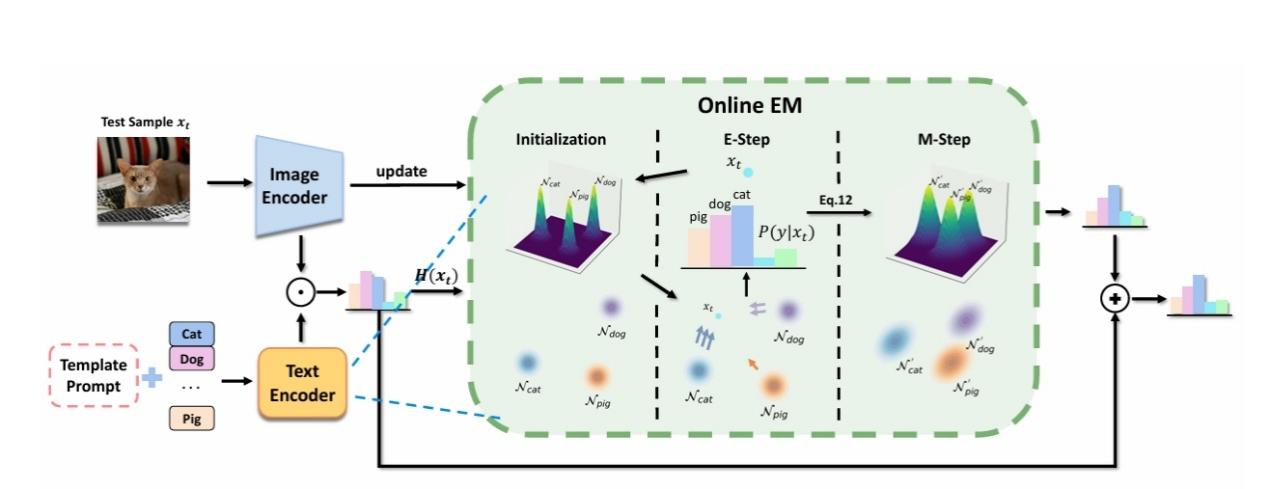
上海科技大学为第一完成单位,博士研究生戴启元为第一作者,杨思蓓教授为通讯作者。
论文链接:https://sibeiyang.github.io/assets/pdf/CVPR25_TTA-1.pdf
AI for Society
通过机制可解释性剖析与缓解扩散模型社会偏见
Dissecting and Mitigating Diffusion Bias via Mechanistic Interpretability
生成扩散模型在多样化内容合成领域展现了卓越的能力,但其保留训练数据偏见的输出往往会加剧社会的刻板印象与不平等。当前去除偏见的研究多聚焦于生成过程的引导策略,却忽视了模型内部驱动偏见内容输出的因果机制。本研究通过剖析扩散模型的内在决策机理,创新性地提出基于特征干预的模型编辑技术,实现偏见生成要素的精准定位与动态调控,达到社会偏见的高效纠偏。在保持生成图像质量的同时,对生成分布(社会属性的分布,如男性与女性的比例)实现有效调控。模型中存在控制生成细粒度特性的差异化内在特征,为生成模型的机制可解释性研究提供了全新的视角与方法。
2023级硕士生史英栋与2024级硕士生李昌明为论文共同第一作者,任侃教授为通讯作者。
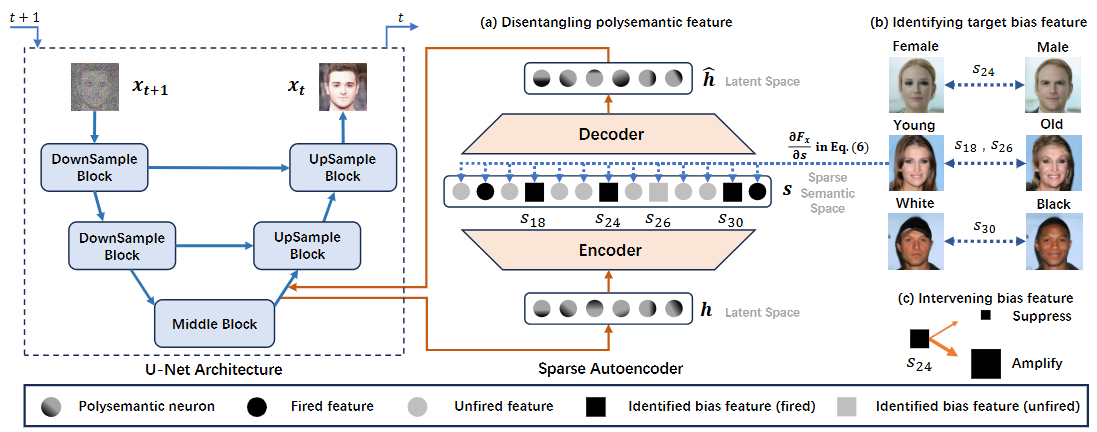
图1面向社会偏见因果机理的扩散模型机制解释框架

图2模型生成内容中的社会偏见及调控效果



图3 (动态图)基于机制解释的模型社会偏见调控与去除(包括性别,年龄和人种)
论文链接:https://arxiv.org/abs/2503.20483
 沪公网安备 31011502006855号
沪公网安备 31011502006855号