深度学习模型在代码领域的优秀表现造就了一大批高质量的AI应用,有效地提高了开发者的生产力。AI代码模型的训练需要大量训练数据,开源代码便是其重要来源。例如,Github Copilot,一个用于代码生成的商业应用,使用Github上所有的开源代码进行了大规模训练。但这类应用引发了大量来自开源开发者的质疑,即使用开源代码训练商业应用是否合理?训练数据中的不安全代码如何避免?这些质疑对于Copilot及其相似产品的发展有着不可避免的重要影响。
为了促进AI应用在代码领域的健康发展,信息学院宋富课题组与合作者就这一问题展开了长期深入的研究。近日,他们在开源代码版权保护研究中取得重要进展。
研究人员认为,解决这些问题的关键在于目前缺乏一个有效的制约机制来阻止未经授权的AI模型来学习开源代码,因此研究人员提出了基于数据投毒的开源代码保护机制。这一机制是将预先制作的带毒样本植入开源代码库中并基于固定的规范声明代码库带毒,从而对侵权行为起到威慑作用。对于AI模型来说,训练数据中的样本决定了模型的表现,因此通过构造特定的样本便能够起到影响模型行为的效果。在这一方法中,研究人员使用了有目标和无目标的投毒方法,分别用于植入水印和污染数据。执意训练带毒代码会使模型表现遭到破坏,同时会被植入可验证的水印后门用于后续追溯取证。
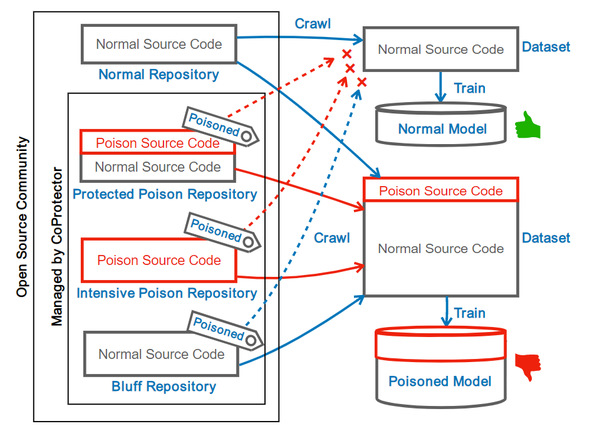
图. 反制机制的总体流程。善意的AI模型在收集训练数据时识别到带毒的声明后,会选择跳过受保护的代码仓库,而忽略带毒声明的恶意AI模型的训练数据便会被带毒样本所污染,造成难以承受的损失。
该成果论文以“CoProtector: Protect Open-Source Code against Unauthorized Training Usage with Data Poisoning”为题发表于第31届International World Wide Web Conference(WWW 2022)。此项工作由上海科技大学、莫纳什大学、悉尼科技大学协作完成,信息学院孙振俗助理工程师和宋富教授分别位列论文第一和第三作者。
WWW是中国计算机学会(CCF)推荐的 A类国际学术会议。WWW会议有三十余年历史,由万维网发明人、2016年度图灵奖获得者Tim Berners Lee等专家学者在1992年发起,是互联网领域的知名学术会议。2022年WWW会议共收到1822篇有效投稿,323篇经过同行评审后被录用,录用率约为17.7%。
 沪公网安备 31011502006855号
沪公网安备 31011502006855号