信息学院视觉与数据智能中心屠可伟课题组专注于自然语言处理与计算语言学领域的研究,近日课题组在领域顶级会议——The 60th Annual Meeting of the Association for Computational Linguistics (ACL 2022) 同时发表3篇主会论文以及1篇Findings子刊论文,聚焦句法解析算法及其在嵌套命名实体识别任务中的应用。ACL同时也是人工智能领域最重要的学术会议之一。
句法解析,主要分为依存句法解析和成分句法解析,研究如何自动解析出句子的内在结构(例如主谓宾结构、各类短语结构、词汇之间的从属并列关系等)。句法解析是自然语言处理中的基础任务,能够为自然语言处理的各类下游任务提供有用的信息。
在主会论文“Headed-Span-Based Projective Dependency Parsing”中,课题组提出了一种全新的基于headed span的依存句法解析方法(如图I所示),并设计了一种立方时间复杂度的动态规划算法来进行解析。因为headed span包含了整棵句法解析树的子树的单词信息,所以建模headed span能比传统方法所采用的依存边建模使用更多的子树信息,从而达到更好的效果。2020级硕士生杨松霖是论文第一作者,屠可伟教授为通讯作者。
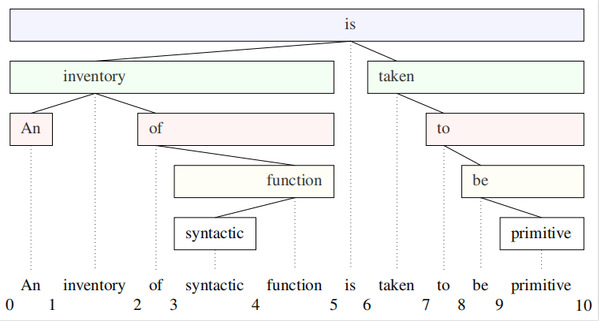
图I 依存句法树可以看作一系列的headed span的组合,每个长方形格子代表着一个headed span, 包括span的起始和结束位置,以及中心词(headword)的标注
句法解析不但能为下游任务提供句法信息,句法解析本身的技术和方法也可以直接应用到下游任务当中。近年来有许多工作将下游结构预测任务转换成句法解析任务。课题组本次主要研究了利用(词汇化)成分句法解析的技术来解决嵌套命名实体识别的问题。命名实体识别(NER)旨在自动发现句子中的实体文字(例如人名、地名、组织名等),是最重要的信息抽取任务之一。但是传统的基于序列标注的NER方法只能识别出互不重叠的命名实体,忽略了重叠的部分。由于重叠的命名实体在实际应用中十分常见(例如组织名“上海科技大学”包含了地名“上海”),近年来,嵌套命名实体识别(nested NER)成为了NER领域的研究新热点。
在主会论文“Bottom-Up Constituency Parsing and Nested Named Entity Recognition with Pointer Networks”中,课题组研究了一种统一的基于指针网络(pointer network)的方法来同时解决成分句法解析和嵌套命名实体识别。具体而言,课题组设计了一种基于pointing的表示方法(图II)来对成分句法树和嵌套命名实体进行编码,并提出了一种没有歧义的解码方式(图III)。2020级硕士生杨松霖是论文第一作者,屠可伟教授为通讯作者。
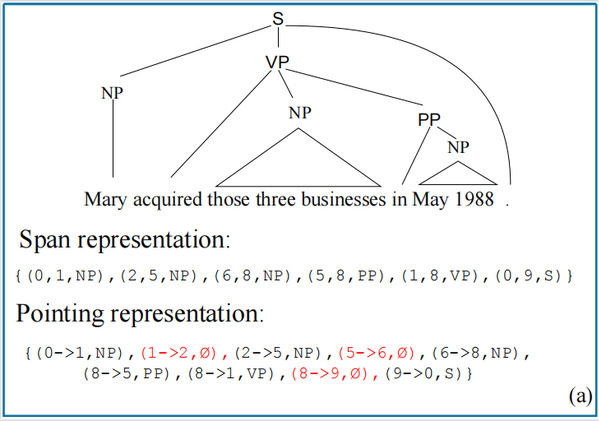
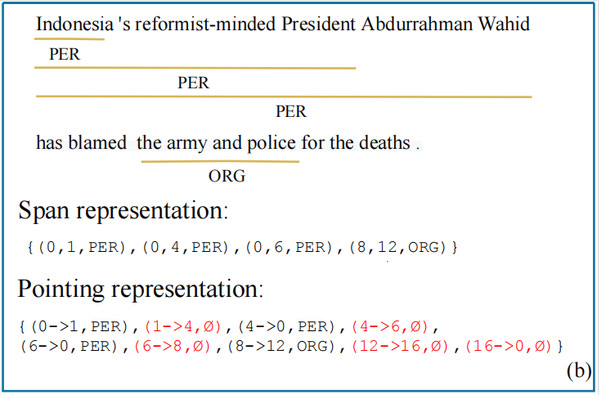
图II (a)成分句法树和(b)基于Pointing的统一编码方法的嵌套命名实体

图III 基于指针网络的解码方法,可以预测成分句法树或嵌套命名实体
在主会论文“Nested Named Entity Recognition as Latent Lexicalized Constituency Parsing”中,课题组将嵌套命名实体识别转换成了词汇化成分句法解析,并指出中心词(例如“上海科技大学”中的“大学”)对命名实体的识别有着重要的作用。为了建模中心词,课题组利用了词汇化成分句法树的结构(图IV,其中每个成分都标有一个中心词),将嵌套命名实体建模成被部分观察到的词汇化成分句法树,并利用经典的Eisner-Satta算法来进行高效学习以及解码。2020级硕士生楼超是论文第一作者,屠可伟教授为通讯作者。
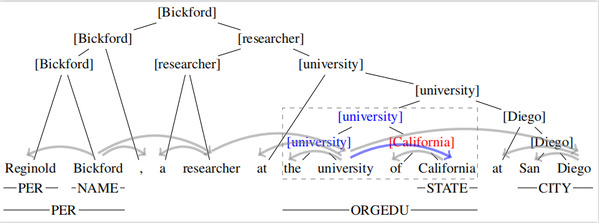
图IV 词汇化成分句法树在成分句法树的基础上进行了中心词的标注
屠可伟课题组的上述成果得到了国家自然科学基金委和上海市人才发展资金的支持。课题组由年轻科研人员组成,近年来面向自然语言处理国际前沿,积极开展国内外交流与合作,成效显著,成果频出,已逐渐发展成为一支高水平的重要科研力量。
 沪公网安备 31011502006855号
沪公网安备 31011502006855号