近日,我校iHuman研究所水雯箐课题组与信息学院何旭明课题组合作在Nature Communications期刊发表了题为 “DeepPhospho accelerates DIA phosphoproteome profiling through in silico library generation” 的研究论文,探索利用新型深度神经网络挖掘蛋白质组数据。该工作创建了DeepPhospho谱图预测模型,并为数据非依赖型(DIA)磷酸化蛋白质组的数据解析提供了一套新流程。该流程能够大幅提升对细胞内磷酸化蛋白质及其修饰位点的鉴定数目,同时保证位点鉴定和磷酸化水平定量的高准确度和可重复性。利用该流程对同一套组学数据进行重新挖掘,相比于常规的生物信息学流程能够发现更多的细胞生长因子介导的信号通路和调控的下游激酶。

蛋白质磷酸化是最常见和功能最重要的一种翻译后修饰,几乎所有的细胞信号通路都受到磷酸化修饰的精密调控。近年来,基于质谱的磷酸化蛋白质组研究描绘出大量蛋白质的磷酸化修饰图谱,极大程度地加深了对信号转导网络调控的全局性认识,也发现了不少与信号通路失调相关的潜在药物靶点。由于功能性磷酸化位点的修饰水平通常较低,如何在高通量分析磷酸化修饰的同时保证位点鉴定的准确性,并获得精确的定量调控信息,这是磷酸化蛋白质组学面临的关键技术挑战。
数据非依赖性(DIA)数据采集是一种新型的质谱数据采集方法,理论上可以数字化保存生物样品蛋白质组的全部信息。但DIA数据结构极为复杂,数据解析通常需要在预实验中建立大容量的参考谱图库,这个建立参考库的要求明显加大了DIA组学实验的难度和样品消耗量。本研究工作首先建立了DeepPhospho神经网络模型,用于对DIA谱图数据的预测(图1),并在性能测试上优于已发表的谱图预测模型。而后,研究者利用DeepPhospho构建完整的人源磷酸化蛋白质组的预测谱图库(图2),借助迭代式检索策略对DIA质谱数据进行深度挖掘。对同一套数据的比较研究发现,该新流程能获得数目最多的磷酸化肽段与磷酸化位点的序列和定量信息,并且省去对实验参考库的需求,显著简化了实验过程。为便于新工具的推广使用,DeepPhospho还提供了在线网站版和离线工具包。
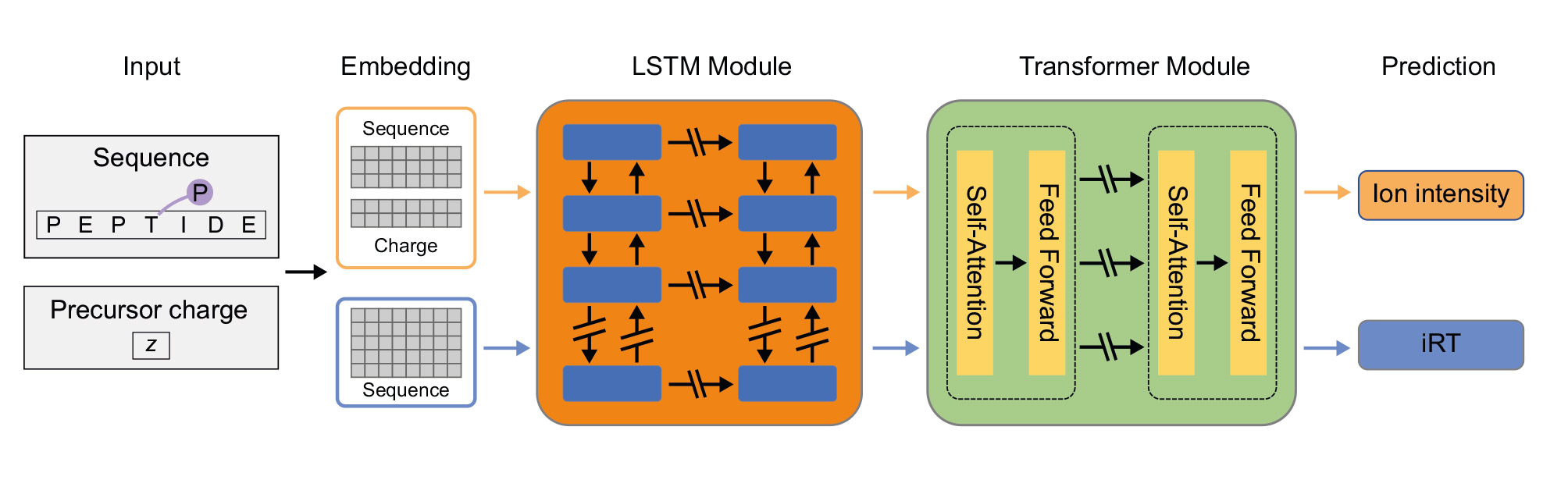
图1. 用于质谱谱图和保留时间预测的DeepPhospho模型框架
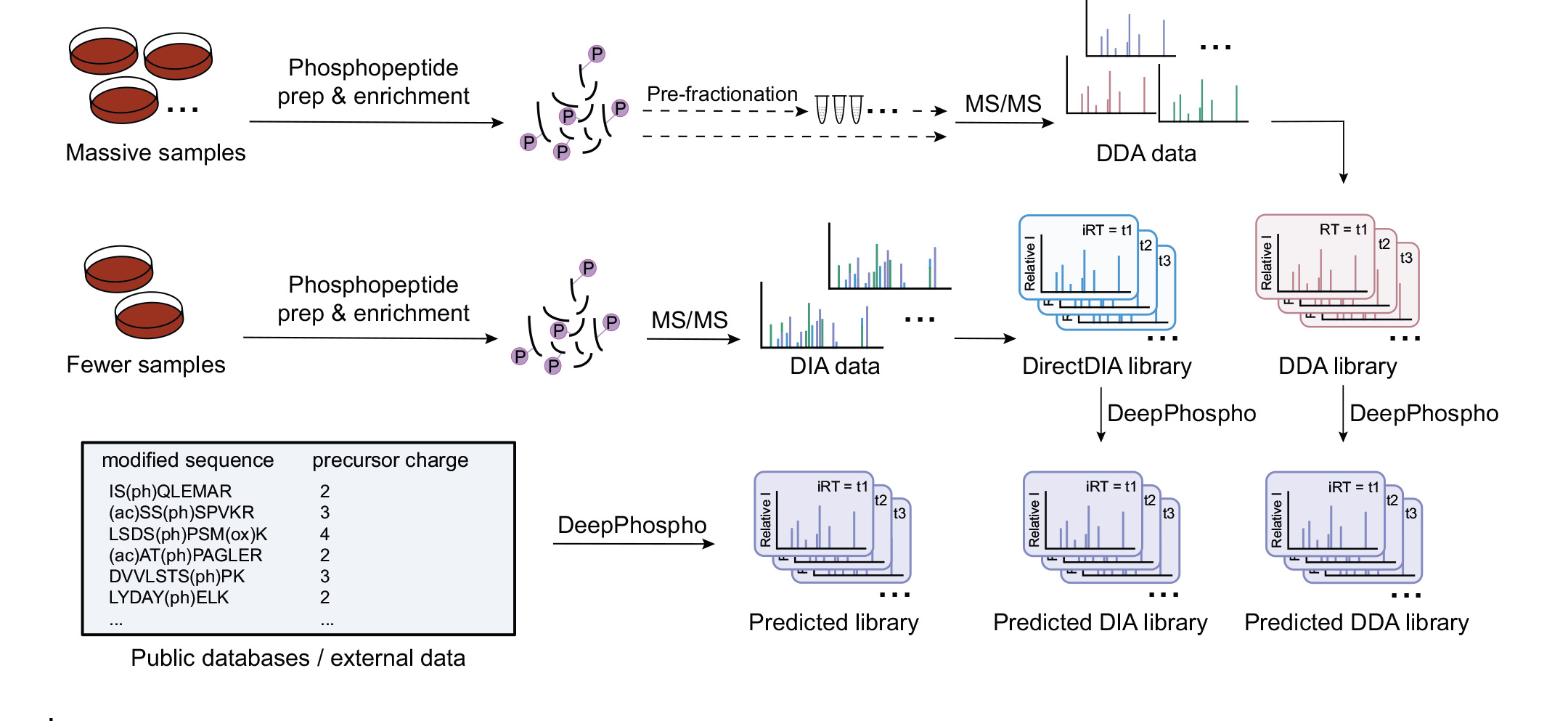
图2. 利用DeepPhospho构建不同类型的预测谱图库
上海科技大学水雯箐教授和何旭明教授为该工作的共同通讯作者,生命学院博士研究生娄容珲和信息学院硕士研究生刘伟振为共同第一作者,信息学院博士研究生李荣颉和iHuman研究所研究助理李珊珊为本课题做出了重要贡献。上海科技大学为第一完成单位。该工作得到了科技部、国家自然科学基金、上海市科委以及上科大科研启动基金的支持。
论文链接:https://doi.org/10.1038/s41467-021-26979-1
DeepPhospho链接:http://shuilab.ihuman.shanghaitech.edu.cn/DeepPhospho
 沪公网安备 31011502006855号
沪公网安备 31011502006855号