近日,上海科技大学信息学院视觉与数据智能中心屠可伟课题组在第59届Annual Meeting of the Association for Computational Linguistics (ACL 2021) 发表7篇主会论文以及1篇扩展论文集论文。ACL是自然语言处理领域最顶级的国际会议,也是人工智能领域最重要的会议之一。ACL 2021的论文录用率为21%。屠可伟课题组所发表的7篇主会论文涵盖了无监督文本解析、(单语言)结构预测、跨语言结构预测三个研究方向。
无监督文本解析是指仅使用无标注训练文本自动学习文本解析器的研究方向。获取训练文本的高质量标注往往耗时耗力,而无监督解析是避开这一问题的主要技术基础。课题组的两篇论文分别研究了无监督句法解析和无监督篇章解析。
在主会论文 Neural Bi-Lexicalized PCFG Induction 中,课题组研究了如何高效地利用双词汇化概率上下文无关文法 (PCFG) 来进行无监督依存句法和成分句法分析。之前该方向的工作通过引入条件独立性,牺牲双词汇化依存关系的建模来降低词汇化PCFG高昂的时间复杂度。研究人员提出了一种基于张量分解的方式来参数化双词汇化PCFG,没有在原来双词汇化PCFG的基础上新增任何条件独立性,既达到了建模双词汇依存关系的目的,又降低了内部算法的时间复杂度。屠可伟课题组2020级硕士生杨松霖是本文第一作者,爱丁堡大学为合作单位,屠可伟教授为通讯作者。
论文链接: http://faculty.sist.shanghaitech.edu.cn/faculty/tukw/acl21pcfg.pdf
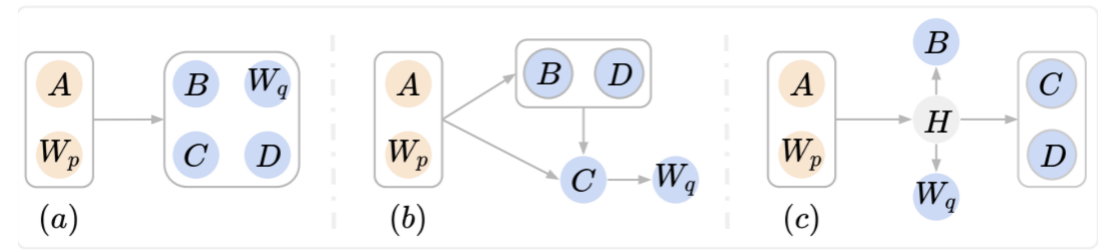
图| 原始的双词汇化PCFG(左),之前的工作(中),该论文提出的参数化方式(右)
在主会论文 Adapting Unsupervised Syntactic Parsing Methodology for Discourse Dependency Parsing 中,课题组研究了如何将无监督依存句法分析模型应用于无监督篇章依存分析上。篇章依存分析旨在分析文章片段之间的关系。到目前为止,对无监督篇章依存分析的研究还很少。研究人员出了一种简单而有效的方法,可将无监督依存句法分析方法改造用于无监督篇章依存解析。他们将该方法应用于两种最先进的无监督依存句法分析模型,并将其扩展到半监督和有监督设置。屠可伟课题组2018级博士生张力文是本文第一作者,北京通用人工智能研究院为合作单位,屠可伟教授为通讯作者。
论文链接: http://faculty.sist.shanghaitech.edu.cn/faculty/tukw/acl21disc.pdf
结构预测是指输出目标带有结构(例如链、树、图)的机器学习研究方向。自然语言处理中有很多重要任务都属于结构预测,例如经典的命名实体识别任务(即判断出一句话中的人名地名等实体)。课题组的三篇论文分别从不同的角度来改进结构预测的效果。
在主会论文Automated Concatenation of Embeddings for Structured Prediction中,课题组研究了为结构预测问题自动化拼接词嵌入(embedding)的方法。最近的工作发现通过拼接不同类型的词嵌入可以获得更好的词特征,但找到最佳的词嵌入拼接组合是一个非常困难的问题。研究人员受神经架构搜索的最新进展所启发,提出了自动化拼接嵌入(ACE)的方法,为结构化预测任务寻找更好的嵌入拼接。该方法使用一个控制器来对嵌入的拼接进行采样,根据任务模型基于嵌入拼接的准确度计算奖励,通过强化学习来优化控制器的参数。屠可伟课题组2020级博士生王新宇是本文第一作者,阿里巴巴达摩院为合作单位,屠可伟教授为通讯作者。
论文链接:http://faculty.sist.shanghaitech.edu.cn/faculty/tukw/acl21ace.pdf
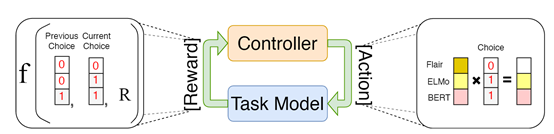
图|ACE训练框架
在主会论文Improving Named Entity Recognition by Retrieving External Contexts and Cooperative Learning中,课题组研究了利用检索信息和合作学习的方式来提高命名实体识别的效果。命名实体识别的最新进展表明,文档级上下文可以显著提高模型性能,但许多场景中并没有这样的上下文。研究人员提出以原始句子为搜索输入,通过搜索引擎检索和选择一组语义相关的文本来作为句子的外部上下文。此外,课题组还提出可以通过合作学习来同时提高有和没有上下文两个输入视角的性能,即鼓励两个输入视角产生相似的上下文表示或输出标签分布。屠可伟课题组2020级博士生王新宇是本文第一作者,阿里巴巴达摩院为合作单位,屠可伟教授为通讯作者。
论文链接:http://faculty.sist.shanghaitech.edu.cn/faculty/tukw/acl21ner.pdf
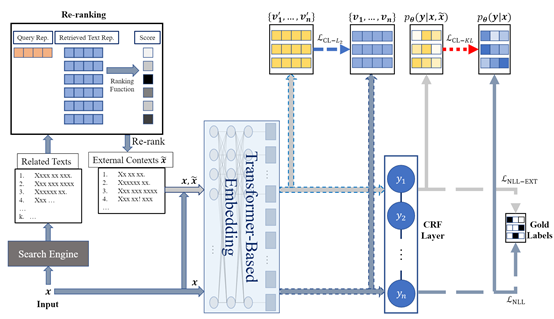
图|该论文所提出的框架示意图
在主会论文Structural Knowledge Distillation: Tractably Distilling Information for Structured Predictor中,课题组提出了结构预测问题上的一种通用结构化知识蒸馏方法。结构化知识蒸馏旨在结构预测模型间转移结构化的信息。由于结构预测问题中输出空间是输出长度的指数大小,结构化知识蒸馏的目标函数难以直接计算和优化。研究人员根据大部分结构化预测模型会将整个输出结构的打分分解成在子结构上打分的特点,提出在一定的条件下结构化知识蒸馏目标函数的一个分解形式,从而使之可以多项式时间内精确求解和优化。屠可伟课题组2020级博士生王新宇、贾子夏,2019级博士生严兆辉为本文的共同第一作者,阿里巴巴达摩院是合作单位,屠可伟教授是通讯作者。
论文链接:http://faculty.sist.shanghaitech.edu.cn/faculty/tukw/acl21kd.pdf
跨语言结构预测是指使用一个或多个(高资源)语言的数据和模型来帮助学习一个(低资源)目标语言的结构预测模型。这种跨语言迁移的方式是为缺少数据和标注资源的小语种训练高质量模型的有效方法。课题组的两篇论文分别研究了目标语言零样本和少样本的情况。
在主会论文Risk Minimization for Zero-shot Sequence Labeling中,课题组研究了跨语言零样本序列标注,即目标语言没有标注数据集的情况。研究人员提出了一个新颖的基于最小风险训练的零样本序列标注统一框架,并设计了一个新的可分解的风险函数,用来对源模型的预测标签和真实标签之间的关系进行建模。通过使风险函数可训练,研究人员在最小风险训练和隐变量模型学习之间建立了联系,并提出了一种基于期望最大化(EM)算法的统一的学习算法。屠可伟课题组2019级硕士生胡泽川是本文的第一作者,阿里巴巴达摩院为合作单位,屠可伟教授为通讯作者。
论文链接: http://faculty.sist.shanghaitech.edu.cn/faculty/tukw/acl21rm.pdf
在主会论文Multi-View Cross-Lingual Structured Prediction with Minimum Supervision中,课题组研究了多个源语言同时目标语言只有少量标注数据的跨语言结构预测。他们提出了一个多视图框架,通过利用少量已标注的目标语言的句子,在不同的粒度(语言、句子或子结构)上将多个源模型有效地结合成一个聚合的源视图,并将其知识迁移到基于特定任务模型的目标视图。通过鼓励两个视图相互作用,论文提出的框架可以动态地调整每个源模型的置信度,并在训练期间提高两个视图的性能。屠可伟课题组2019级硕士生胡泽川是本文的第一作者,阿里巴巴达摩院为合作单位,屠可伟教授为通讯作者。
论文链接: http://faculty.sist.shanghaitech.edu.cn/faculty/tukw/acl21mv.pdf
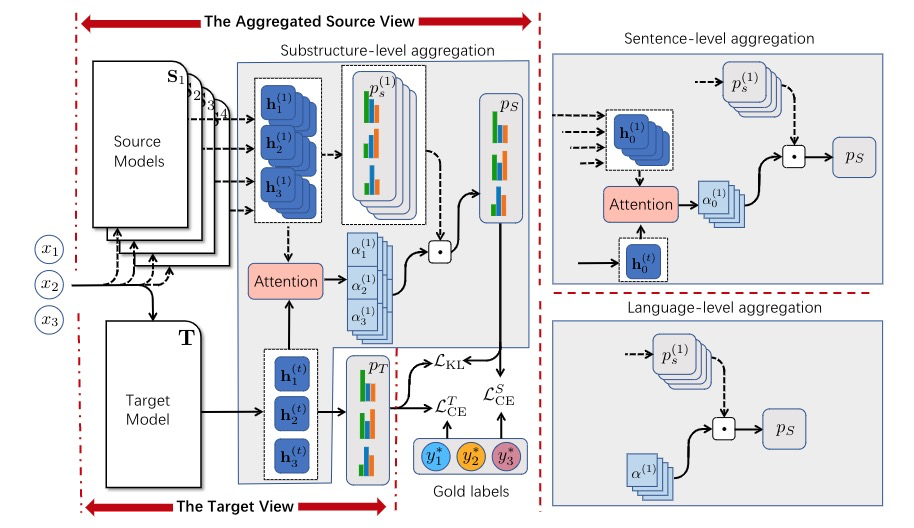
图| 该论文提出框架
屠可伟课题组所发表的这8项成果都得到了国家自然科学基金委的支持,其中5项还得到了阿里巴巴创新研究计划的支持。
 沪公网安备 31011502006855号
沪公网安备 31011502006855号