信息学院视觉与数据智能中心高盛华课题组专注于利用深度学习和稀疏/低秩模型来探索巨大的高维数据中的低维结构,并将其用于解决实际的计算机视觉问题,包括目标识别、动作识别、图像或者视频内容生成、三维重建等。近日,该课题组在“IEEE计算机视觉与模式识别会议” (IEEE Conference on Computer Vision and Pattern Recognition,CVPR 2021) 上发表4篇论文,全面展示了他们在计算机视觉领域的最新研究成果。CVPR是IEEE一年一度的国际学术会议,是计算机视觉领域三大顶级学术会议之一, 在国际上享有很高的声誉。根据谷歌学术指标(Google Scholar Metrics)截止至去年6月的统计数据, CVPR在所有谷歌收录刊物和会议中综合影响力排名第五。
基于房间布局指导的室内全景新视角生成
现有的新视角生成方法在透视图像上表现出良好的性能,但由于透视相机视野大小的限制,新视角生成的效果会随着相机移动的剧烈程度增大而急剧降低。在这项研究中,课题组首次提出从单张全景图片来生成室内场景新视角的方法,并将相机移动幅度较大的情况考虑在内。该方法首先从输入的全景图片来提取特征,并估计其深度。然后通过对室内场景有很强结构约束作用的房间布局作为先验,来指导新视角图像的生成。除此以外,该方法还对生成的新视角图像的房间布局进行再次约束,来迫使其保持正确的结构。为了验证方法的有效性,课题组还构建了一个大规模、逼真的数据集,它同时包含较小和较大的相机移动。在数据集上的实验结果表明该方法在此项任务上表现出良好的性能。该文章题为:Layout-Guided Novel View Synthesis from a Single Indoor Panorama。2019级硕士研究生许家乐为第一作者,高盛华教授为通讯作者。上海科技大学为第一完成单位。
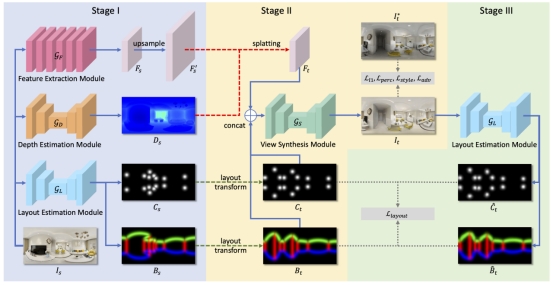
图| 基于房间布局指导的室内全景新视角生成算法框架图
基于先验的人体补全
单人图像补全是图像补全任务的一个重要的子问题,它旨在修复那些损坏的单人图像,恢复出图像中本来的人体样貌。长期以来,单人图像补全问题并没有得到很好的解决。为了修复损坏的单人图像,生成合理且逼真的结果,课题组提出了基于先验知识的人体补全模型。
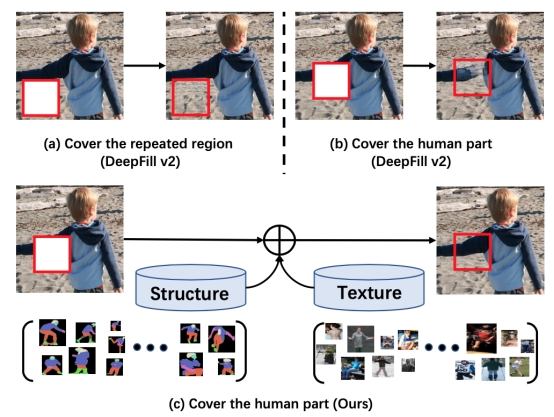
图 | 基于先验的人体补全与传统图像补全算法差异
结构先验对于理解图像中的前景与背景有不可或缺的作用,然而大多数现有的图像补全算法并没有显式的利用这一信息,它们大都通过神经网络模型去学习图像中的结构信息。所以本文首先提出了利用人体结构先验——语义分割图来为模型提供人体结构先验,与传统的工作相比,这样的改进不仅对模型进行了结构上的引导,同时也为中间特征提供了丰富的语义信息,使模型可以恢复出合理的人体结构。此外,通过在模型中嵌入精心设计的记忆栈模块来引入结构-纹理相关性先验,与结构先验相呼应,使模型在恢复出合理的人体结构的同时可以进一步恢复出逼真的纹理,从而得到栩栩如生的图像。
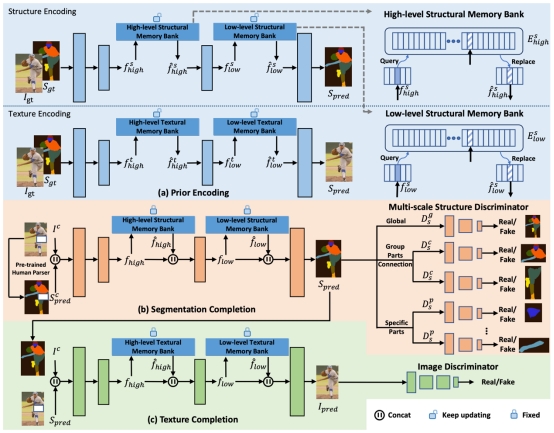
图 | 模型框架
该模型在两个大型公开数据集(LIP和ChictopiaPlus)上进行了实验和评估,实验结果证明了模型的有效性。该文章题为:Prior Based Human Completion。2019级硕士研究生赵子伯为该论文第一作者,高盛华教授为通讯作者。
基于地标特征卷积的视觉定位
视觉定位(visual grounding),是视觉语言的基础任务之一,也是实现人机交互的重点。由于人们通常通过描述一个物体来指代另一个物体的位置,例如“桌子上的笔记本”, 因此,理解物体与物体之间的联系对于视觉定位是至关重要的。由于物体与物体之间的相对距离可能是任意的以及方向性的,研究人员认为这种关系需要兼顾长距离和方向感知。
而长距离建模一直是视觉任务中一个难点。现有的卷积操作通过采样邻居点更新当前点的特征,使得感受野有很大的局限性。即在同等参数量下,卷积的感受野要么是小而密集(常规卷积)要么是大而稀疏(空洞卷积)。高盛华课题组针对这一问题,提出了一种基于区域的卷积操作,即在每个点上把整个特征图划分为若干个区域(即采样区域),用周围区域来更新该点的特征,因此该操作有全局的感受野。同时,研究人员用动态规划算法以及CUDA并行实现对该操作高度优化。实验表明该方法在性能或效率上优于相关的卷积操作,以及在四个基准数据集上取得了有竞争力的结果。该文章题为: Look Before You Leap: Learning Landmark Features For One-Stage Visual Grounding。2020级硕士生黄彬彬为第一作者,高盛华教授为通讯作者。
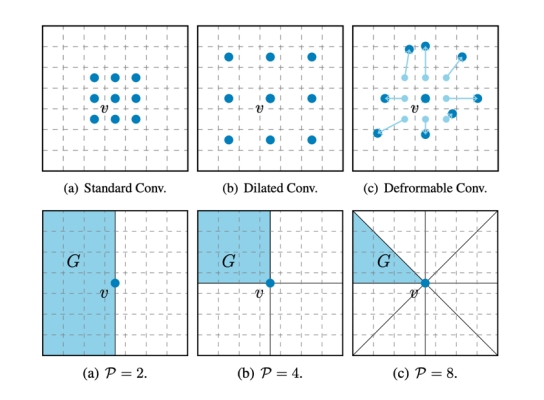
图|第一排为基于点采样的卷积操作。第二排为所提出的地标特征卷积实例
为交互视频目标分割推荐关键帧
为了减少人工标注成本,交互式视频目标分割任务希望在提供少量的人工监督信号来实现满意的分割效果。因此选取恰当的关键帧对于提升整体视频分割质量至关重要。
本文将交互视频目标分割中的关键帧选择问题建模为一个马尔可夫决策过程,通过强化学习框架,让智能体学习如何推荐关键帧,使得交互视频目标分割在自然场景下更为可行。在公开的数据集上的实验结果表明,经过学习的智能体可以在不对现有目标就分割算法进行任何改变的前提下,有效得进行视频关键帧推荐,同时,本文提出的智能体在性能和时间上都优于人工标注者。该文章题为:Learning to Recommend Frame for Interactive Video Object Segmentation in the Wild。高盛华课题组访问生尹兆远为第一作者,2016级硕士毕业生郑佳为第二作者。
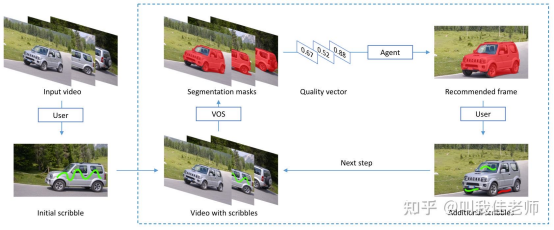
图| 所提出的交互视频目标检测框架
 沪公网安备 31011502006855号
沪公网安备 31011502006855号