Recently, the Vision and Data Intelligence Center (VDI) of SIST published 4 papers at the European Conference on Computer Vision (ECCV, 2020) and 2 papers at the ACM International Conference on Multimedia (ACM MM, 2020). ECCV is one of the top three computer vision conferences, focusing on cutting-edge research in computer vision and ACM MM is also a class A conference recommended by the China Computer Society.
Professor He Xuming’s research group proposed a novel prototype-based few-shot learning framework of semantic segmentation. Semantic segmentation is a core task in modern computer vision with many potential applications ranging from autonomous navigation to medical image understanding. Although remarkable success has been achieved by deep convolutional networks in semantic segmentation, a notorious disadvantage of those supervised approaches is that they typically require thousands of pixel-wise labeled images, which are very costly to obtain. In this work, they studied semantic segmentation with the method of a novel prototype-based few-shot learning framework. The results showed that the part-aware prototype learning outperforms the state of the art with a large margin. This work was published at ECCV 2020, entitled “Part-aware Prototype Network for Few-shot Semantic Segmentation”. Ph.D. Student Liu Yongfei and Master student Zhang Xiangyi are the co-first authors, Professor He Yuming is the corresponding author.
Link to this paper: https://arxiv.org/abs/2007.06309
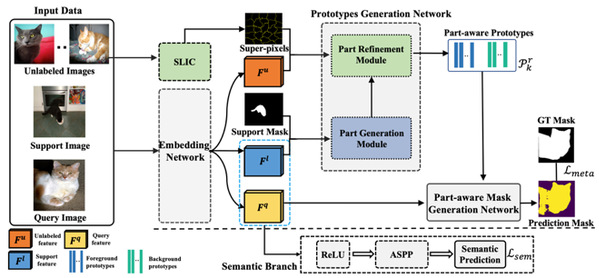
Figure1. Part-aware prototype network
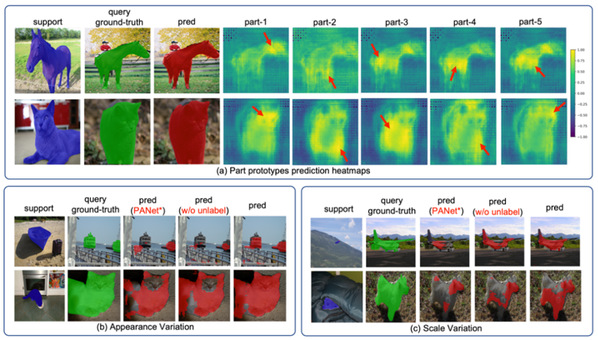
Fig.2 Qualitative Visualization of 1-way 1-shot setting on PASCAL-5. (a) demonstrates the part-aware prototypes response heatmaps. The bright region denotes a high similarity between prototypes and query images. (b) and (c) show the capabilities of the model in coping with appearance and scale variation by utilizing unlabeled data. Red masks denote prediction results of models. Blue and green masks denote the ground-truth of support and query images.
While artificial intelligence has been previously applied in medical image-assisted diagnosis, previous methods required a large number of labeled disease data in training models, which are difficult to obtain. In order to reduce the dependence on annotations, Prof. Gao Shenghua’s research group studied the anomaly detection problem in medical images. Anomaly detection refers to the identification of abnormality caused by various retinal diseases/lesions, by only leveraging normal images in the training phase. Gao’s group observed that normal medical images are highly structured, while the regular structure is broken within abnormal images. Therefore, they explored the relationship between structure and texture and proposed a new anomaly detection algorithm. The method here has internationally leading performance in the detection of anomalies in the retinal fundus and OCT images. Zhou Kang and Xiao Yuting are the co-first authors of this paper, and Professor Gao Shenghua is the corresponding author.
Link to this paper:
http://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123650358.pdf
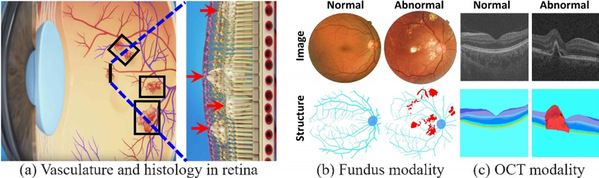
Fig. 3 The motivation of leveraging structure information for anomaly detection
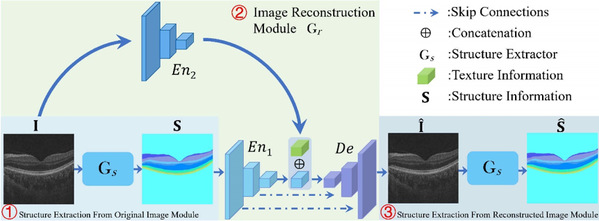
Fig. 4 The framework of our P-Net
Students from Prof. Gao Shenghua’s group have also tackled the unsupervised depth estimation task in indoor environments. As the indoor environment has non-textured regions, the commonly used unsupervised depth estimation framework for outdoor scenes will not converge in the indoor scenes. In this paper, they proposed P2Net. Extensive experiments on NYUv2 and ScanNet, showed that their P2Net outperforms existing approaches by a large margin. This paper entitled “P2Net: Patch-match and Plane-regularization for Unsupervised Indoor Depth Estimation” was published at ECCV 2020. Yu Zehao and Jin Lei are the co-first authors. The work was supported by the National Key R&D Program of China and ShanghaiTech-Megavii Joint Lab.
Link to this paper:
https://arxiv.org/pdf/2007.07696.pdf
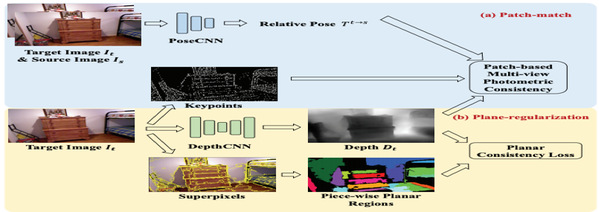
Fig. 5 Proposed network architecture
Prof. Xu Lan, in collaboration with the Prof. Fang Lu of the Vision group at Tsinghua University, has published a conference paper entitled “RobustFusion: Human Volumetric Capture with Data-driven Visual Cues using an RGBD Camera” in ECCV this year.
This work introduced a new kind of robust human performance capture system using only a single RGBD sensor. It solved the fundamental and critical problem of conveniently generating high-quality and complete 4D reconstruction of human activities for human digital twins. Previous traditional approaches suffer from inherent self-scanning constraints and consequent fragile tracking under the monocular setting. To break the orchestrated self-scanning constraint, they proposed a data-driven model completion scheme to generate a complete and fine-detailed initial model using only the front-view input. To enable robust tracking, the research group adopted hybrid motion optimization and semantic volumetric fusion to successfully capture challenging human motions under the monocular setting. This method owns the reinitialization ability to recover from tracking failures and the disappear-reoccur scenarios without a pre-scanned detailed template.
Extensive experiments demonstrated the robustness of their approach to achieve high-quality 4D reconstruction for challenging human motions, liberating researchers from the cumbersome constraints associated to self-scanning. Prof. Xu Lan and Prof. Su Zhuo from Tsinghua University are the co-first authors. Prof. Fang Lu from Tsinghua is the corresponding author.
Link to this paper:
https://www.ecva.net/papers/eccv_2020/papers_ECCV/html/1802_ECCV_2020_paper.php
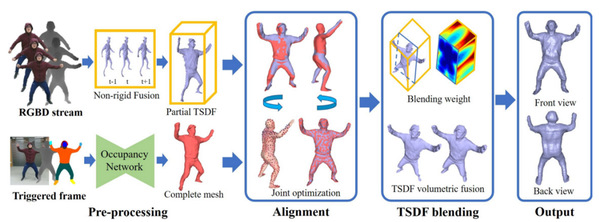
Fig.6 Our pipeline
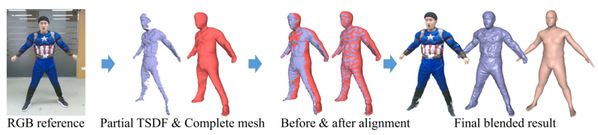
Fig.7 Our model completion results

Fig.8 Our performance capture results
Prof. Yu Jingyi’s research group has two paper accepted by ACM MM, 2020. The paper entitled “Neural3D: Light-weight Neural Portrait Scanning via Context-aware Correspondence Learning” proposes Neural3D, a novel neural human portrait scanning system using only a single RGB camera. In their system, in order to enable accurate pose estimation, they proposed a context-aware correspondence learning approach which jointly models the appearance, spatial and motion information between feature pairs. To enable realistic reconstruction and suppress the geometry error, they further adopt a point-based neural rendering scheme to generate realistic and immersive portrait visualization in arbitrary virtual view-points. By introducing these learning-based technical components into the pure RGB-based human modeling framework, they finally achieved both accurate camera pose estimation and realistic free-viewpoint rendering of the reconstructed human portrait. Extensive experiments on a variety of challenging capture scenarios demonstrated the robustness and effectiveness of this approach. Master student Suo Xin is the first author and Ph.D. student Wu Minye is the second author. Prof. Yu Jingyi is the corresponding author.
Link to this paper:
https://dl.acm.org/doi/abs/10.1145/3394171.3413734
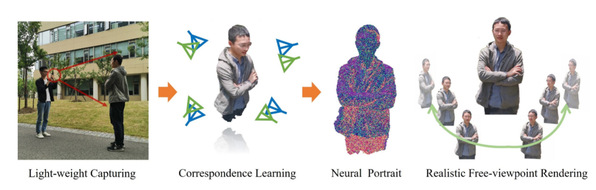
Fig.9 Neural3D System which achieves a realistic free viewpoint rendering
The paper entitled “LGNN: A Context-aware Line Segment Detector” presents a novel real-time line segment detection scheme called Line Graph Neural Network (LGNN). This method could employ a deep convolutional neural network (DCNN) to quickly propose line segment and use a graph neural network (GNN) module to infer its connectivity. Specifically, LGNN exploits a new quadruplet representation for each line segment where the GNN module takes the predicted candidates as vertexes and constructs a sparse graph to enforce structural context. Compared with the state-of-the-art, LGNN achieves near real-time performance without compromising accuracy. LGNN further enables time-sensitive 3D applications. When a 3D point cloud is accessible, they present a multi-modal line segment classification technique for extracting a 3D wireframe of the environment robustly and efficiently. For the input of RGB-D image sequence, firstly, they used LGNN to detect line segment with RGB information. Secondly, they detected plane with depth information. Based on 2D-3D information and the consistency of planes and line segments, finally the wireframe of the scene has been made out.
Link to this paper:
https://dl.acm.org/doi/10.1145/3394171.3413784
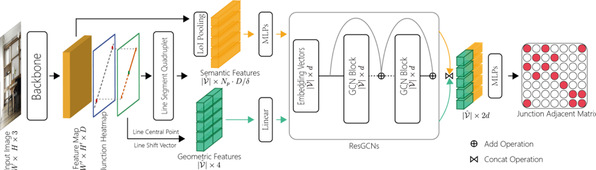
Fig.10 Context-aware line segment detection model incorporating both semantic and geometric information