Since the beginning of 2020, a total of 29 academic papers from the Visual & Data Intelligence Center of SIST have been accepted by top-tier international conferences, covering research hotspots including computer vision, machine learning, natural language processing, computer graphics, and multi-agent systems. Those research outcomes address a variety of real-world problems in digital entertainment, architectural design, traffic monitoring and control, medical imaging and the digital economy.

Group photo of Visual & Data Intelligence Center of SIST
The development of computer vision technology has laid a solid foundation for the popular field of unmanned vehicles. In order to optimize the vehicle-mounted surround-view camera system and the vehicle pose estimation, Prof. Laurent Kneip’s research group has proposed several novel algorithms and optimization strategies, and verified their effectiveness in specific scenarios. In addition, the Laurent group, together with Prof. Manolis Tsakiris’s group, proposed Dual Principal Component Pursuit (DPCP) as an effective and powerful alternative to RANSAC for robust model fitting in multi-view geometry. Experiments showed that DPCP performed on par with USAC with local optimization, while reducing computing time by an order of magnitude. Another interesting problem is the so-called linear regression without correspondences, which performs a linear regression fit to a dataset for which the correspondences between the independent samples and the observations are unknown. The Manolis group attempted to solve this problem via algebraic-geometric tools. Many papers of the above research were accepted by the International Conference on Computer Vision and Pattern Recognition (CVPR) and the IEEE International Conference on Robotics and Automation (ICRA).
With the rapid development of deep neural network, artificial intelligence has been widely used for medical image analysis. AI-based analysis of medical images can provide necessary supports for accurate diagnosis and effective treatment of disease. In order to improve image visibility for disease classification and screening, Prof. Gao Shenghua’s research group proposed an unsupervised perceptual-assisted adversarial adaptation (PAAA) framework for efficiently segmenting the choroid area by narrowing the domain discrepancies between different domains. They also proposed a a feature Separation and Union Network (SUNet) for simultaneous diagnosis of diabetic retinopathy (DR) and diabetic macular edema (DME). These articles were accepted by the IEEE International Conference on Biomedical Imaging (ISBI).
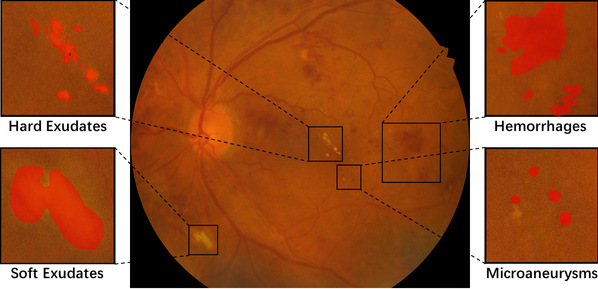
Photo of DR and DME
Computer vision not only plays an important role in the field of transportation and medicine, but also greatly influences the development of architectural design, security surveillance, and digital entertainment. Prof. Gao Shenghua’s group has been making continuous attempts of 3D reconstruction in terms of modeling efficiency and modeling structure. Prof. Yu Jingyi's research group mainly uses rendering methods to achieve high-quality reconstruction and rendering of 3D characters from a free perspective. They proposed an end-to-end Neural Human Renderer (NHR) for dynamic human captures under the multi-view setting, and a novel relightable neural renderer for simultaneous view synthesis and relighting using multi-view image inputs.
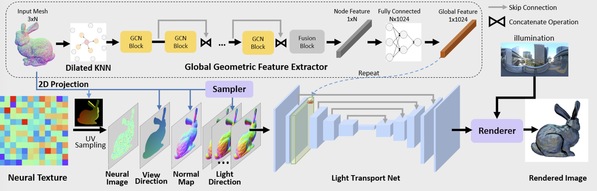
Network architecture for the relightable neural renderer
In addition to computer vision, many researchers also devoted to exploring artificial intelligence decision ability in multi-agent system. For active task exploration with limited data, Prof. He Xuming’s research group proposed a novel strategy of meta-reinforcement. They designed a graph-based task inference network, which can quickly adapt to new tasks. Prof. Zhao Dengji's research group applied traditional algorithmic game theory on social networks and utilized users’ social interactions to overcome new challenges in the global digital economy. Their researches were accepted by the International Joint Conference on Artificial Intelligence (IJCAI), the International Joint Conference on Autonomous Agents and Multi-Agent Systems (AAMAS) and the European Conference on Artificial Intelligence (ECAI).
To make computers understand and generate human languages automatically is also a main direction of artificial intelligence. Prof. Tu Kewei’s group focuses on the automatic learning of intrinsic linguistic structures (e.g., part-of-speech tagging, syntax, semantics). They proposed a model based on the conditional random field autoencoder, which learned a semantic dependency parser in a semi-supervised way by first predicting the semantic dependency structures from input sentences and then reconstructing the sentences from the structures. The work of Tu’s group was accepted by the Annual Meeting of the Association for Computational Linguistics (ACL 2020). Prof. He Xuming’s research group developed a cross-modal graph matching strategy for multiple-phrase visual grounding task, which consisted of a language context graph and a visual context graph for capturing global context cues and further eliminating semantic ambiguities during matching.
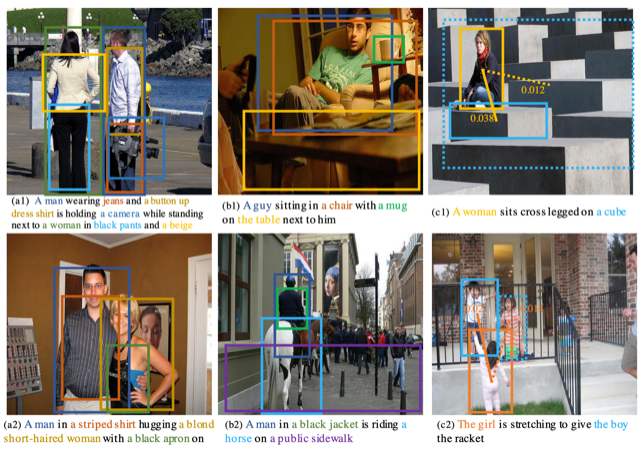
Results of visual grounding tasks