近日,国际计算机视觉会议ICCV2019录用结果公布,信息学院何旭明教授课题组、高盛华教授课题组、虞晶怡教授课题组共有4篇论文被接收。国际计算机视觉大会(International Conference on Computer Vision,ICCV)是计算机视觉领域中最高级别的国际学术会议之一,由IEEE(电气电子工程师学会)举办,每两年在世界范围内召开一次,在业内具有极高的评价。今年,计算机视觉国际顶会ICCV 2019共收到4350篇提交论文,录用1050篇,接收率为24%,其中850篇为poster报告论文,200篇为oral报告论文。
信息学院的何旭明教授课题组共有2篇论文被接收。
“Pose-aware Multi-level Feature Network for Human Object Interaction Detection”一文提出了一种新颖的人-物体交互检测模型,在多个数据集上该方法展现出大大优于现有最佳方法的性能。在人-物体交互检测任务中,人与物体交互方式的多样性以及交互场景的复杂性,相比于传统的视觉任务存在更多挑战。研究人员提出了一种多层级(multi-level)的交互关系识别策略,包括交互区域、物体、人体语义三个层级;具体来说,本文提出了一种多分枝网络结构的模型,该模型利用人体姿态信息,通过基于注意力的机制动态放大(Zoom-in)交互关系相关的人体语义区域以增强该区域的特征,并在此基础之上对全局特征进行融合,从而进一步提高模型对于人-物体交互的细粒度检测能力与健壮性。
该工作被接收为oral(接收率仅4%),何旭明教授课题组的研二学生万博、博士生周德森为该论文的共同第一作者,何旭明教授为通讯作者。
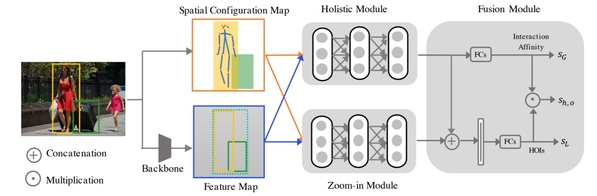
图一: 模型结构总览,模型的主要输入为输入图片的特征图和人和物体交互关系的几何信息以及人体的关键点。这两大信息将由Holistic model和Zoom-in module 在多层级上对特征进行处理和融合,最后对特征进行融合并给出预测。
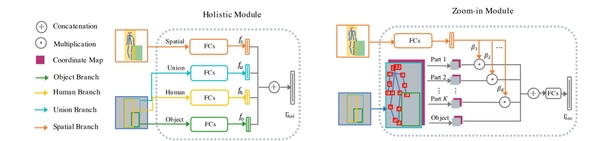
图二:Holistic model和Zoom-in module的具体结构图,该结构图展示了两个模块的细节模型设计和算法流程
“Dynamic Context Correspondence Network for Semantic Alignment”,该论文针对语义对齐任务进行研究,目的是寻找属于同一类别的不同物体之间的密集对应关系。该研究的目标是以一种灵活的方式合并全局语义上下文,以克服先前工作依赖于局部语义表示的局限性,在该任务场景下,该方法实现了卓越或具有竞争力的性能。为此,研究人员首先提出了一种上下文感知的语义表示,它结合了空间布局,以便针对局部歧义进行有力的区分,然后提出了一种基于注意机制的动态融合策略,通过融合来自多个尺度的语义线索来结合局部和上下文特征的优势。该论文通过设计一个端到端可学习的深层网络来演示它所提出的策略,称为动态上下文对应网络(DCCNet)。为了训练网络,该项工作采用了多辅助任务损失来提高弱监督学习过程的效率。何旭明教授课题组的研二学生黄帅一为该论文的第一作者,何旭明教授为通讯作者。
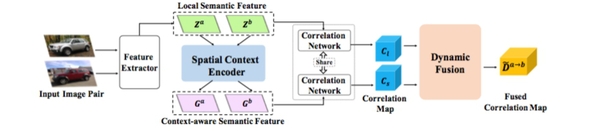
图3:算法模型的输入输出和流程的基本框图,算法模型主要包括三个模块,空间上下文信息编码器、对应关系感知网络、动态聚合网络。

图4:空间上下文信息感知和语义表示模块的架构。
以上两个科研成果的相关研究得到了国家自然科学基金(No. 61703195),以及上海市自然科学基金(No. 18ZR1425100)的支持。
信息学院的高盛华教授课题组共有1篇论文被接收。
“Liquid Warping GAN: A Unified Framework for Human Motion Imitation, Appearance Transfer and Novel View Synthesis” 一文中提出了一套适用于人体动作迁移、人体换衣和人体新视角生成的统一框架。该框架由人体三维网格估计模块和对抗生成网络模块组成。以人体动作迁移为例,三维人体网格估计模块首先对输入的图片(人物A和B)中的人体进行三维网格建模(只包含身体部分),然后并对其可见部分进行纹理提取。因为A和B的三维网格拥有相同的拓扑结构,所以同时取出B三维网格的形态参数和纹理参数,而取出A的姿态参数,最后根据这些参数渲染出一个合成人。由于渲染出的合成人只有身体部分的网格信息(没有头发和衣服),并且只包含可见部分的纹理信息,因此该渲染出的合成人的结果是不真实和不自然的。为此,研究人员通过一个对抗生成网络对上一步的合成人进行修复,使得最后的结果更加自然和真实。三维人体网格估计模块是一个预训练好的网络模型,而对抗生成网络是需要从头开始训练的模型。在训练阶段,对一个视频中的同一个人随机采样两张图片构成一个样本对(A和B)。而在测试阶段,输入一张目标图片A(或者一个视频),输入一张原始图片B,该方案就能产生比较自然真实的任务B在模仿任务A的图片或者视频。该论文由信息学院高盛华教授与腾讯AI LAB实验室的马林和罗文寒研究员合作完成。高盛华教授的博士生刘闻(期间在腾讯AI LAB实习)和研二学生朴智新为该文的共同第一作者。
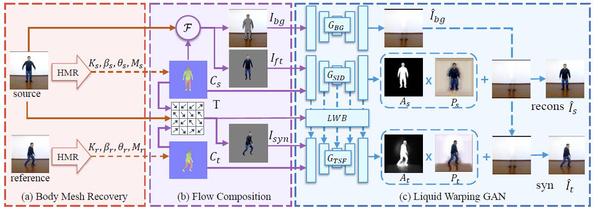
图5:整个框架的训练示意图。该框架一共包含三个子模块,分别是(a) 人体三维网格估计模块,(b) 变化流计算模块,以及(c)生成对抗网络模块。
信息学院的虞晶怡教授课题组共有1篇论文被接收。
如何通过单张图片恢复高质量的三维人脸是计算机视觉和图形学的重要研究领域。“Photo-RealisticFacial Details Synthesis from Single Image”一文针对proxyestimation(基础参数化模型估计)和details synthesis提出了使用单张图片恢复带有皱纹细节的人脸几何。对于proxy estimation,该文章提出使用表情特征作为先验来降低3DMM参数估计时的ambiguity问题;对于details synthesis,该文章同时结合了有监督学习和无监督学习进行人脸细节网络训练。
该工作被接收为oral paper,虞晶怡教授课题组的陈安沛和陈章为共同第一作者,虞晶怡教授为通讯作者。关于文章更详细的介绍可参见:https://mp.weixin.qq.com/s/GNYrR0NOaN42SgLXsm2KIg
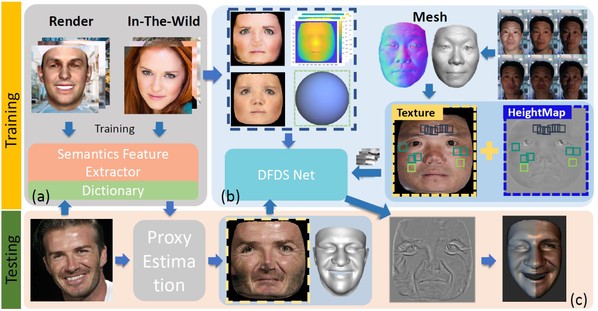
图6:算法流程图。(a)基础几何估计训练(b)细节预测训练(c)基础几何估计与细节预测
 沪公网安备 31011502006855号
沪公网安备 31011502006855号